这是本节的多页打印视图。
点击此处打印 .
返回本页常规视图 .
上手 在你的笔记本/云服务器上部署 Pigsty 单机版本,访问数据库以及 Web 用户界面
Pigsty 采用可伸缩的架构设计,既可用于 超大规模生产环境 单机开发演示环境
如果您打算学习了解 Pigsty,可以从 快速上手
您可以利用一台 Linux MiniPC,云厂商提供的免费/优惠虚拟机,Windows 的 WSL,或者在自己的笔记本上创建虚拟机用于 Pigsty 部署。
Pigsty 提供了开箱即用的 Vagrant Terraform
单机版本的 Pigsty 包含了所有核心功能,440+ 个 PG 扩展 IaC PITR 数据持久性 高可用
如果您想要在没有互联网连接的环境中安装 Pigsty,请参考 离线安装 精简安装 部署指南
快速开始 准备 SSH 权限 节点 兼容的 Linux 系统 sshsudo管理用户
curl -fsSL https://repo.pigsty.cc/get | bash # 安装 Pigsty 与依赖
cd ~/pigsty; ./configure -g # 生成配置(使用默认单机配置模板,-g 参数会生成随机密码)
./deploy.yml # 执行部署剧本,完成部署
是的,就是这么简单。您完全可以在不了解任何细节的情况下,使用 预制配置模板
接下来,您可以探索 图形用户界面 PostgreSQL 数据库服务 配置定制 执行剧本
1 - 快速上手 Pigsty 单机部署 快速上手 Pigsty,从一台全新的 Linux 主机开始,完成单机安装部署!
本文是 Pigsty 单节点安装指南,生产环境的多节点高可用部署请参考 部署
Pigsty 单机安装分为三步走:安装 配置 部署
摘要 准备 SSH 权限 节点 兼容的 Linux 系统 sshsudo管理用户
pigsty.cc(中国)
pigsty.io(全球) curl -fsSL https://repo.pigsty.cc/get | bash;
curl -fsSL https://repo.pigsty.io/get | bash;
该命令会执行 安装 配置 部署
cd ~/pigsty # 进入 Pigsty 目录
./configure -g # 生成配置文件(可选,如果知道如何配置可以跳过)
./deploy.yml # 执行部署剧本,根据生成的配置文件开始安装
安装完成后,您可以通过 IP / 域名 + 80/443 端口访问 Web 用户界面 5432 端口访问 PostgreSQL 服务
完整流程根据服务器规格/网络条件需 3~10 分钟,离线安装 精简安装
视频样例:在线单机安装(Debian 13, x86_64)
准备 安装 Pigsty 涉及一些 准备工作
项目 要求 项目 要求 节点 单节点 ,至少 1C2G,上不封顶磁盘 /data 作为默认主挂载点,建议使用 xfs系统 Linux x86_64 / aarch64,EL / Debian / Ubuntu网络 静态 IPv4 地址,单节点无固定 IP 可使用 127.0.0.1 SSH 通过公钥 nopass SSH 登陆纳管节点 SUDO sudo 权限,最好带有 nopass 免密选项
通常您只需要关注本机 IP 地址 —— 作为特例,单机部署时,如果没有静态 IP 地址,可以使用 127.0.0.1 代替。
安装 您可以使用以下命令自动安装 Pigsty 源码包至 ~/pigsty 目录(推荐),部署所需依赖(Ansible)会自动安装。
pigsty.cc(中国)
pigsty.io(全球) curl -fsSL https://repo.pigsty.cc/get | bash # 安装最新稳定版本
curl -fsSL https://repo.pigsty.cc/get | bash -s v4.0.0 # 安装特定版本
curl -fsSL https://repo.pigsty.io/get | bash # 安装最新稳定版本
curl -fsSL https://repo.pigsty.io/get | bash -s v4.0.0 # 安装特定版本
如果您不希望执行远程脚本,可以手动 下载 git 克隆安装时,请务必检出特定版本后再使用。
git clone https://github.com/pgsty/pigsty; cd pigsty;
git checkout v4.0.0-b4; # 使用 git 安装时,请务必检出特定版本
手工下载克隆安装时,请额外执行 boostrap自行安装
./bootstrap # 安装 ansible,用于执行后续部署
配置 在 Pigsty 中,部署的蓝图细节由 配置清单 pigsty.yml
Pigsty 提供了 configure配置向导 配置清单
./configure -g # 使用配置向导生成配置文件,并且生成随机密码
配置过程生成的配置文件默认位于:~/pigsty/pigsty.yml,您可以在安装前进行检查,按需修改与定制。
有许多 配置模板 pigsty.yml 配置文件进行定制。
./configure # 使用默认模板,安装默认的 PG 18,带有必要扩展
./configure -v 17 # 使用 PG 17 的版本,而非默认的 PG18
./configure -c rich # 创建本地软件仓库,下载所有扩展,安装主要扩展
./configure -c slim # 最小安装模板,与 ./slim.yml 剧本一起使用
./configure -c app/supa # 使用 app/supa 自托管 supabase 配置模板
./configure -c ivory # 使用 ivorysql 内核而非原生 PG
./configure -i 10.11.12.13 # 显式指定主 IP 地址
./configure -r china # 使用中国镜像而非默认仓库
./configure -c ha/full -s # 使用 4 节点沙箱配置模板,不进行 IP 替换和探测
配置 / configure 过程的样例输出 vagrant@meta:~/pigsty$ ./configure
configure pigsty v4.0.0 begin
[ OK ] region = china
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = deb,apt
[ OK ] vendor = ubuntu ( Ubuntu)
[ OK ] version = 22 ( 22.04)
[ OK ] sudo = vagrant ok
[ OK ] ssh = [email protected] ok
[ WARN] Multiple IP address candidates found:
( 1) 192.168.121.38 inet 192.168.121.38/24 metric 100 brd 192.168.121.255 scope global dynamic eth0
( 2) 10.10.10.10 inet 10.10.10.10/24 brd 10.10.10.255 scope global eth1
[ OK ] primary_ip = 10.10.10.10 ( from demo)
[ OK ] admin = [email protected] ok
[ OK ] mode = meta ( ubuntu22.04)
[ OK ] locale = C.UTF-8
[ OK ] ansible = ready
[ OK ] pigsty configured
[ WARN] don' t forget to check it and change passwords!
proceed with ./deploy.yml
配置脚本常用参数 :
参数 说明 -i|--ip当前主机的首要内网 IP 地址,用于替换配置文件中的 IP 地址占位符 10.10.10.10 -c|--conf用于指定使用的 配置模板 conf/ 目录,不带 .yml 后缀的配置名称 -v|--version用于指定要安装的 PostgreSQL 大版本,如 13、14、15、16、17、18 -r|--region用于指定上游软件源的区域,加速下载: (default|china|europe) -n|--non-interactive直接使用命令行参数提供首要 IP 地址,跳过交互式向导 -x|--proxy使用当前环境变量配置 proxy_env
如果您的机器网卡绑定了多个 IP 地址,那么需要使用 -i|--ip <ipaddr> 显式指定一个当前节点的首要 IP 地址,或在交互式问询中提供。
该脚本将把 IP 占位符 10.10.10.10 替换为当前节点的主 IPv4 地址。选用的地址应为静态 IP 地址,请勿使用公网 IP 地址。
修改默认密码!
我们强烈建议您在安装前,事先修改配置文件中使用的默认密码与凭据,详情参考 安全建议
部署 Pigsty 的 deploy.yml剧本 配置
./deploy.yml # 一次性在当前节点上部署所有定义的模块
部署过程的样例输出 ......
TASK [ pgsql : pgsql init done ] *************************************************
ok: [ 10.10.10.11] = > {
"msg" : "postgres://10.10.10.11/postgres | meta | dbuser_meta dbuser_view "
}
......
TASK [ pg_monitor : load grafana datasource meta] *******************************
changed: [ 10.10.10.11]
PLAY RECAP *********************************************************************
10.10.10.11 : ok = 302 changed = 232 unreachable = 0 failed = 0 skipped = 65 rescued = 0 ignored = 1
localhost : ok = 6 changed = 3 unreachable = 0 failed = 0 skipped = 1 rescued = 0 ignored = 0
当您看到输出尾部如果带有 pgsql init done,PLAY RECAP 等字样,说明安装已经完成!
上游软件仓库变更可能导致在线安装失败!
Pigsty 使用的上游软件仓库(如 Linux / PGDG 仓库)可能会因为不恰当的更新,进入崩溃状态并导致部署失败(有过多次先例)!
您可以选择等待上游仓库修复后安装,或者使用预制的 离线软件包
避免重复执行部署剧本!
警告: 在已经完成部署的环境中再次完整运行 deploy.yml
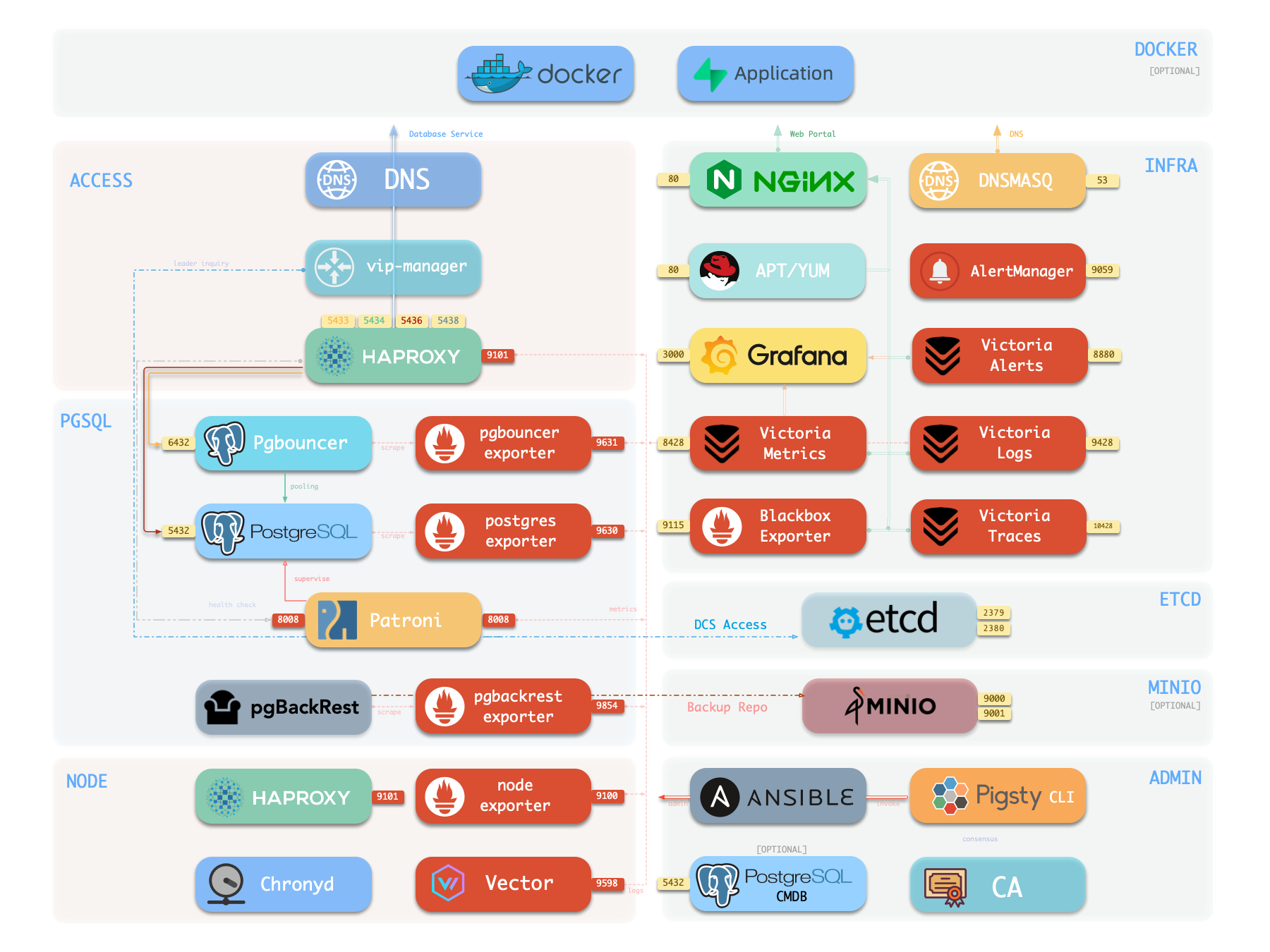
界面 Pigsty 单机安装完成后,您在当前节点上通常会安装有四个功能模块:
PGSQLINFRANODEETCD
INFRA图形化管理界面 80/443 端口访问。
PGSQLPostgreSQL 数据库服务器 5432 端口,也可通过 Pgbouncer / HAProxy 代理访问
更多 您可以以当前节点作为基础,部署和监控 更多集群 配置清单
bin/node-add pg-test # 将集群 pg-test 的 3 个节点纳入 Pigsty 管理
bin/pgsql-add pg-test # 初始化一个 3 节点的 pg-test 高可用 PG 集群
bin/redis-add redis-ms # 初始化 Redis 集群: redis-ms
大多数模块都需要先安装 NODE模块
PGSQLINFRANODEETCDMINIOREDISFERRETDOCKER
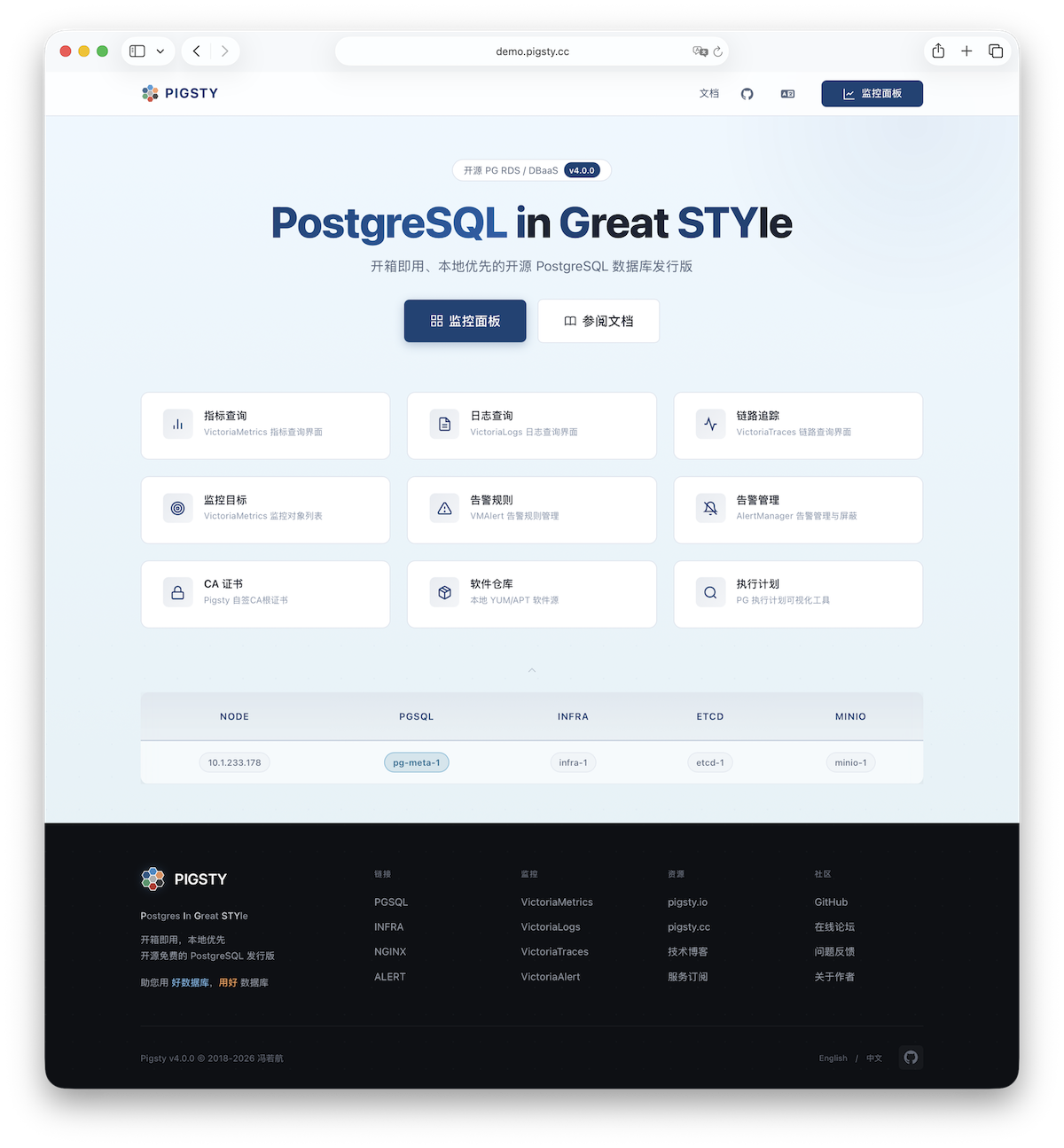
2 - 从浏览器访问图形用户界面 探索 Pigsty 提供的 Web 图形管理界面,Grafana 大盘,以及如何通过域名和 HTTPS 访问它们。
Pigsty 单机安装 INFRA
其中的默认服务器配置提供了一个 WebUI 图形界面,用于展示监控仪表盘,并统一代理访问其他组件的 Web 界面。
访问 您可以通过在浏览器中键入部署节点 IP 地址来访问这个图形界面。在默认配置下,Nginx 将通过 80/443 标准端口对外提供服务。
监控 要访问 Pigsty 的监控系统大盘(Grafana),您可以访问服务器的 /ui 端点。
如果您的服务对互联网与办公网开放,我们建议您通过 域名 HTTPS
端点 在默认配置下,Nginx 会在 80/443 端口的默认服务器上,通过不同的路径暴露以下端点:
域名访问 如果您有自己的域名,可以将其解析到 Pigsty 服务器的 IP 地址,从而通过域名访问 Pigsty 提供的各项服务。
如果您希望启用 HTTPS,则应当修改 infra_portalhome
all :
vars :
infra_portal :
home : { domain : i.pigsty } # 将 i.pigsty 替换为你的域名
all :
vars :
infra_portal : # domain 指定域名 # certbot 参数指定证书名称
home : { domain: demo.pigsty.cc ,certbot : mycert }
您可以在部署完成后,执行 make cert 命令为该域名申请免费的 Let’s Encrypt 证书。
如果您没有定义 certbot 字段,Pigsty 会默认使用本地 CA 签发自签名的 HTTPS 证书,
在这种情况下,您必须首先信任 Pigsty 的自签名 CA 才可以在浏览器中正常访问。
您还可以将本地目录与其他上游服务挂载到 Nginx 上,更多管理预案,请参考 INFRA 管理 - Nginx
3 - 快速上手 PostgreSQL 快速上手 PostgreSQL,使用命令行与图形客户端连接上 PostgreSQL 并开始使用。
PostgreSQL
本指南面向有基础 Linux 基本命令行操作经验、但对 PostgreSQL 不太熟悉的开发者,带你快速上手 Pigsty 中的 PG。
我们假设您是个人用户,使用默认单机模式进行部署。关于生产环境多节点高可用集群的使用,请参考 生产服务接入
基本知识 默认 单机安装 pg-meta 的 PostgreSQL 数据库集群,只有一个主库实例。
PostgreSQL 监听在 5432 端口,集群中带有一个预置的数据库 meta 可供使用。
您可以在安装完毕后退出当前管理用户 ssh 会话,并重新登陆刷新环境变量后,
通过简单地敲一个 p 回车,通过命令行工具 psql 访问该数据库集群:
vagrant@pg-meta-1:~$ p
psql ( 18.1 ( Ubuntu 18.1-1.pgdg24.04+2))
Type "help" for help.
postgres = #
您也可以切换为操作系统的 postgres 用户,直接执行 psql 命令,即可连接到默认的 postgres 管理数据库上。
连接数据库 想要访问 PostgreSQL 数据库,您需要使用 命令行工具 或者 图形化客户端 工具,填入 PostgreSQL 的 连接字符串 :
postgres://username:password@host:port/dbname
一些驱动和工具也可能会要求你分别填写这些参数,通常以下五项为必选项:
参数 说明 示例值 备注 host数据库服务器地址 10.10.10.10换为你的节点 IP 地址或域名,本机可以省略 port端口号 5432PG 默认端口,可以省略 username用户名 dbuser_dbaPigsty 默认的数据库管理员 password密码 DBUser.DBAPigsty 默认的管理员密码,(请修改密码 ) dbname数据库名 meta默认模板的数据库名称
个人使用时可以直接使用 Pigsty 默认的数据库超级用户 dbuser_dba 进行连接和管理,数据库管理用户 dbuser_dba 拥有数据库的全部权限。
默认情况下,如果您在配置 Pigsty 时指定了 configure -g 参数,密码会随机生成,并保存在 ~/pigsty/pigsty.yml 文件中,可以通过以下命令查看:
cat ~/pigsty/pigsty.yml | grep pg_admin_password
默认账号密码 Pigsty 的默认 单机模板
用户名 密码 角色 用途 dbuser_dbaDBUser.DBA超级用户 数据库管理(请修改密码 ) dbuser_metaDBUser.Meta业务管理员 应用读写(请修改密码 ) dbuser_viewDBUser.Viewer只读用户 数据查阅(请修改密码 )
例如,你可以通过三个不同的连接串,使用三个不同的用户连接到 pg-meta 集群的 meta 数据库:
请注意,这些默认密码会在 configure -g 时自动被替换为随机强密码,请注意将 IP 地址和密码替换为实际值。
使用命令行工具 psql 是 PostgreSQL 官方命令行客户端工具,功能强大,是 DBA 和开发者的首选工具。
在部署了 Pigsty 的服务器上,你可以直接使用 psql 连接本地数据库:
# 最简单的方式:使用 postgres 系统用户本地连接(无需密码)
sudo -u postgres psql
# 使用连接字符串(推荐,通用性最好)
psql 'postgres://dbuser_dba:[email protected] :5432/meta'
# 使用参数形式
psql -h 10.10.10.10 -p 5432 -U dbuser_dba -d meta
# 使用环境变量避免密码出现在命令行
export PGPASSWORD = 'DBUser.DBA'
psql -h 10.10.10.10 -p 5432 -U dbuser_dba -d meta
成功连接后,你会看到类似这样的提示符:
psql ( 18.1)
Type "help" for help.
meta = #
常用 psql 命令
进入 psql 后,可以执行 SQL 语句,也可以使用以 \ 开头的元命令:
命令 说明 命令 说明 Ctrl+C中断查询 Ctrl+D退出 psql \?显示所有元命令帮助 \h显示 SQL 命令帮助 \l列出所有数据库 \c dbname切换到指定数据库 \d table查看表结构 \d+ table查看表的详细信息 \du列出所有用户/角色 \dx列出已安装的扩展 \dn列出所有的模式 \dt列出所有表
执行 SQL
在 psql 中直接输入 SQL 语句,以分号 ; 结尾:
-- 查看 PostgreSQL 版本
SELECT version ();
-- 查看当前时间
SELECT now ();
-- 创建一张测试表
CREATE TABLE test ( id SERIAL PRIMARY KEY , name TEXT , created_at TIMESTAMPTZ DEFAULT now ());
-- 插入数据
INSERT INTO test ( name ) VALUES ( 'hello' ), ( 'world' );
-- 查询数据
SELECT * FROM test ;
-- 删除测试表
DROP TABLE test ;
使用图形客户端 如果你更喜欢图形界面,以下是几款流行的 PostgreSQL 客户端:
Grafana
Pigsty INFRAGrafana 浏览器图形界面
Grafana 默认的用户名是 admin配置清单 grafana_admin_passwordpigsty)。
DataGrip
DataGrip
DBeaver
DBeaver
pgAdmin
pgAdmin
Pigsty 在 软件模板:pgAdmin
查阅监控大盘 Pigsty 提供了许多 PostgreSQL 监控面板
推荐先从 PGSQL Overview 开始浏览,面板中的许多元素都可以点击,您可以逐层深入,查阅每个集群、实例、数据库甚至是表,索引,函数等数据库内对象的详情信息。
尝试扩展插件 PostgreSQL 最强大的特性之一是其 扩展生态系统
Pigsty 提供了 PG 生态中独一无二的 440+ 扩展 默认配置模板 加装
\ dx -- psql 元命令,列出已经安装的扩展
TABLE pg_available_extensions ; -- 查询已经安装,可以启用的扩展
CREATE EXTENSION postgis ; -- 启用 postgis 扩展
下一步 恭喜你完成了 PostgreSQL 的基础上手!下一步,你可以开始对你的数据库进行一些 配置与定制
4 - 通过配置清单定制 Pigsty 部署 使用声明式的配置文件,表达你需要的基础设施与集群。
除了使用 配置向导 配置清单
如果您事先就在 配置清单 deploy.yml 剧本一把梭,即可完成所有部署工作,但它隐藏了所有细节。
所以本文档会把所有模块与剧本拆解开来,介绍如何从一个简单的配置,通过增量添加的方式,形成一套复杂完备的部署。
最小配置 最简单的有效配置文件可能如下所示,唯一的内容是定义 admin_ip管理节点 )
all : { vars : { admin_ip : 10.10.10.10 } }
# 天朝自有国情在此,额外配置 region: chian 以使用国内的镜像源加速下载
all : { vars : { admin_ip: 10.10.10.10, region : china } }
这个配置不会部署任何东西,但是执行 ./deploy.yml 剧本时,会在 files/pki/ca 生成一套自签名的 CA ,用于签发证书。
为了方便起见,我们还可以额外设置 regiondefault,china,europe)。
加入节点 Pigsty 的 NODE
all : # 不要忘了将 10.10.10.10 替换为您的实际 IP 地址
children : { nodes : { hosts : { 10.10.10.10 : {} } } }
vars :
admin_ip : 10.10.10.10 # 当前节点 IP 地址
region : default # 全球默认软件仓库
node_repo_modules : node,pgsql,infra # 添加 node, pgsql, infra 软件仓库
all : # 不要忘了将 10.10.10.10 替换为您的实际 IP 地址
children : { nodes : { hosts : { 10.10.10.10 : {} } } }
vars :
admin_ip : 10.10.10.10 # 当前节点 IP 地址
region : china # 使用中国镜像
node_repo_modules : node,pgsql,infra # 添加 node, pgsql, infra 软件仓库
为了让这个配置更有用,我们添加了两个 全局参数 node_repo_modulesregion
上面的两个参数能够让节点使用正确的软件仓库,安装默认指定的必须包。
在 NODE 模块中有许多可用的 定制项
接下来,执行 deploy.yml 剧本,或者更精确地执行 node.yml 剧本,将会把这里定义节点 “纳入 Pigsty 管理”,调整至默认配置描述的状态。
加入基础设施 一套功能完备的 RDS 云数据库服务需要基础设施的支持,例如,监控系统(指标/日志采集,告警,可视化),NTP,DNS 等各种基础性服务。
现在,我们通过定义一个特殊的分组 infra,来部署 INFRA
all : # 只是简单的改了个分组名 nodes -> infra,并添加新的实例变量 infra_seq
children : { infra : { hosts : { 10.10.10.10 : { infra_seq : 1 } } } }
vars :
admin_ip : 10.10.10.10
region : default
node_repo_modules : node,pgsql,infra
all : # 只是简单的改了个分组名 nodes -> infra,并添加新的实例变量 infra_seq
children : { infra : { hosts : { 10.10.10.10 : { infra_seq : 1 } } } }
vars :
admin_ip : 10.10.10.10
region : china
node_repo_modules : node,pgsql,infra
同时,我们还分配了一个 身份参数 infra_seqINFRA 模块时将不同的节点区分开来。
执行 infra.yml 剧本,将在 10.10.10.10 上安装 INFRA NODE
./infra.yml # 在 infra 分组上安装 INFRA 模块(连带安装 NODE 模块)
只要 IP 地址存在,NODE 模块会隐含定义。NODE 模块也是幂等的,即使重复执行一次,也没有什么副作用。
安装完成后,您将拥有一套完整的可观测性基础设施,以及节点监控功能,但 PostgreSQL 数据库服务尚未部署。
如果您的目的就是设置这一套监控系统(Grafana + Victoria),那么到此为止就大功告成了!infra模块化 的:您可以只部署监控基础设施,而不部署数据库服务;
或者反过来 —— 在没有基础设施的情况下,运行高可用 PostgreSQL 集群 —— 精简安装
部署数据库集群 要提供 PostgreSQL 服务,您还需要额外安装 PGSQL ETCD
all :
children :
infra : { hosts : { 10.10.10.10 : { infra_seq : 1 } } }
etcd : { hosts : { 10.10.10.10 : { etcd_seq : 1 } } } # 新增 etcd 集群
pg-meta : { hosts : { 10.10.10.10 : { pg_seq: 1, pg_role: primary } }, vars : { pg_cluster : pg-meta } } # 新增 pg 集群
vars : { admin_ip: 10.10.10.10, region: default, node_repo_modules : node,pgsql,infra }
all :
children :
infra : { hosts : { 10.10.10.10 : { infra_seq : 1 } } }
etcd : { hosts : { 10.10.10.10 : { etcd_seq : 1 } } } # 新增 etcd 集群
pg-meta : { hosts : { 10.10.10.10 : { pg_seq: 1, pg_role: primary } }, vars : { pg_cluster : pg-meta } } # 新增 pg 集群
vars : { admin_ip: 10.10.10.10, region: china, node_repo_modules : node,pgsql,infra }
我们在这里添加了两个新的分组:etcd 与 pg-meta,分别定义了一个单节点的 etcd 集群和一个单节点的 PostgreSQL 集群。
您可以使用 ./deploy.yml 重新部署所有内容,也可以使用以下命令进行增量部署:
./etcd.yml -l etcd # 在 etcd 组上安装 ETCD 模块
./pgsql.yml -l pg-meta # 在 pg-meta 组上安装 PGSQL 模块
PGSQL ETCD
至此,我们用 node.ymlinfra.ymletcd.ymlpgsql.yml剧本
定义数据库与用户 您不仅可以定制在哪些节点上安装哪些模块,还可以定制 PostgreSQL 集群的内部细节,例如 数据库 用户
all :
children :
# 隐藏其他分组与变量以简化展示
pg-meta :
hosts : { 10.10.10.10 : { pg_seq: 1, pg_role : primary } }
vars :
pg_cluster : pg-meta
pg_users : # 定义数据库用户
- { name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin] ,comment : admin user }
pg_databases : # 定义业务数据库
- { name: meta ,baseline: cmdb.sql ,comment : pigsty meta database }
Pigsty 提供了非常丰富的定制参数,覆盖了数据库与用户的方方面面。
如果您事先定义好了上面两个参数描述所需的数据库与用户,那么它们会在 ./pgsql.yml用户 数据库
bin/pgsql-user pg-meta dbuser_meta # 确保 pg-meta 集群中有用户 dbuser_meta
bin/pgsql-db pg-meta meta # 确保 pg-meta 集群中有数据库 meta
配置 PG 版本与扩展 您可以安装 不同大版本 440 扩展插件
./pgsql-rm.yml -l pg-meta # 移除旧的 pg-meta 集群(因为它是 PG 18)
我们可以通过定制参数,让集群默认安装并启用一些常用的扩展:timescaledb、postgis 和 pgvector:
all :
children :
infra : { hosts : { 10.10.10.10 : { infra_seq : 1 } } }
etcd : { hosts : { 10.10.10.10 : { etcd_seq : 1 } } } # 新增 etcd 集群
pg-meta :
hosts : { 10.10.10.10 : { pg_seq: 1, pg_role : primary } }
vars :
pg_cluster : pg-meta
pg_version : 17 # 指定 PG 版本为 17
pg_extensions : [ timescaledb, postgis, pgvector ] # 安装这些扩展
pg_lib : 'timescaledb,pg_stat_statements,auto_explain' # 预加载这些扩展动态库
pg_databases : { { name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions : [ vector, postgis, timescaledb ] } }
pg_users : { { name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin] ,comment : admin user } }
vars :
admin_ip : 10.10.10.10
region : default
node_repo_modules : node,pgsql,infra
./pgsql.yml -l pg-meta # 安装 PG17 和扩展重新创建 pg-meta 集群
添加更多节点 我们可以向部署中添加更多节点,将其纳入 Pigsty 的管理之中,部署监控,配置仓库,安装软件 ……
一次添加整个集群,或者逐个添加节点
bin/node-add pg-test
bin/node-add 10.10.10.11
bin/node-add 10.10.10.12
bin/node-add 10.10.10.13
部署高可用PG集群 现在假设我们要在刚添加的三个新节点上,部署一套新的数据库集群 pg-test,采用三节点高可用架构,只需要:
all :
children :
infra : { hosts : { 10.10.10.10 : { infra_seq : 1 } } }
etcd : { hosts : { 10.10.10.10 : { etcd_seq: 1 } }, vars : { etcd_cluster : etcd } }
pg-meta : { hosts : { 10.10.10.10 : { pg_seq: 1, pg_role: primary } }, vars : { pg_cluster : pg-meta } }
pg-test :
hosts :
10.10.10.11 : { pg_seq: 1, pg_role : primary }
10.10.10.12 : { pg_seq: 2, pg_role : replica }
10.10.10.13 : { pg_seq: 3, pg_role : replica }
vars : { pg_cluster : pg-test }
部署 Redis 集群 Pigsty 提供了可选的 Redis 支持,可作为 PostgreSQL 前端的缓存服务。
bin/redis-add redis-ms
bin/redis-add redis-meta
bin/redis-add redis-test
Redis 高可用设置需要使用集群模式或哨兵模式,详情请参阅 Redis 配置
部署 MinIO 集群 Pigsty 提供了可选的开源对象存储,S3 替代 —— MinIO 备份存储仓库
严肃的生产环境 MinIO 部署通常需要至少 4 个节点,每个节点配备 4 块硬盘(4N/16D)。
部署 Docker 模块 如果您想要使用容器运行一些 管理 PG 的工具 使用 PostgreSQL 的软件 DOCKER
你可以使用预制的应用配置模板,一键拉起一些常见的软件工具,例如用于 PG 管理的 GUI 工具: Pgadmin
./app.yml -l infra -e app = pgadmin
甚至,您还可以用 Pigsty 自建 企业级质量的 Supabase
5 - 使用 Ansible 剧本完成部署 使用 Ansible 剧本部署与管理 Pigsty 集群
Pigsty 使用 Ansible
Ansible 可以使用 声明式 的方式对服务器进行配置管理,所有模块的部署都是通过一系列幂等的 Ansible 剧本
例如,在单机部署时,您会用到 deploy.yml内置剧本
了解 Ansible 基础知识有助于更好的使用 Pigsty,但这 并非必须 ,特别是在单机部署时。
部署剧本 Pigsty 提供了一个 “一条龙” 部署剧本 deploy.yml
Playbook 命令 分组 infra[nodes]etcdminio[pgsql]infra.yml./infra.yml-l infra✓ ✓ node.yml./node.yml✓ etcd.yml./etcd.yml-l etcd✓ minio.yml./minio.yml-l minio✓ pgsql.yml./pgsql.yml✓
这是最简单的部署方式,您也可以参考 定制指南
安装 Ansible 使用 Pigsty 安装脚本 bootstrapansible 及其依赖。
如果您想手动安装 Ansible,可以参考以下说明,支持的 Ansible 最低版本为 2.9
sudo apt install -y ansible python3-jmespath
sudo dnf install -y ansible python-jmespath # EL 10
sudo dnf install -y ansible python3.12-jmespath # EL 9/8
brew install ansible
pip3 install jmespath
修改默认密码!
请注意,目前 EL10 EPEL 仓库尚未提供完整的 Ansible 包,Pigsty PGSQL
Ansible 在 macOS 上也可用。您可以使用 Homebrew
执行剧本 Ansible 剧本(Playbook)是包含要执行的一系列任务定义的的可执行 YAML 文件。
执行剧本需要您的环境变量 PATH 中有 ansible-playbook 可执行文件。
运行 ./node.yml 剧本本质上是执行 ansible-playbook node.yml 命令。
您可以使用一些参数来精细控制剧本的执行,其中以下 4 个参数 需要您了解,以便有效使用 Ansible:
目的 参数 描述 对象 -l|--limit <pattern>限制在特定 分组 / 主机 / 模式 上执行 任务 -t|--tags <tags>只运行具有特定标签的任务 参数 -e|--extra-vars <vars>额外的命令行参数 配置 -i|--inventory <path>使用特定的清单文件
./node.yml # 在所有主机上运行 node 剧本
./pgsql.yml -l pg-test # 在 pg-test 集群上运行 pgsql 剧本
./infra.yml -t repo_build # 运行 infra.yml 的子任务 repo_build
./pgsql-rm.yml -e pg_rm_pkg = false # 删除 pgsql,但保留软件包(不卸载软件)
./infra.yml -i conf/mynginx.yml # 使用另外一个位置的配置文件
限制主机 剧本的 执行目标 可以通过 -l|--limit <selector> 限制。
当尝试在特定主机/节点或组/集群上运行剧本时,这很方便。
以下是主机限制的一些示例:
./pgsql.yml # 在所有主机上运行(危险!)
./pgsql.yml -l pg-test # 在 pg-test 集群上运行
./pgsql.yml -l 10.10.10.10 # 在单个主机 10.10.10.10 上运行
./pgsql.yml -l pg-* # 在匹配 glob 模式 `pg-*` 的主机/组上运行
./pgsql.yml -l '10.10.10.11,&pg-test' # 在 pg-test 组的 10.10.10.11 上运行
./pgsql-rm.yml -l 'pg-test,!10.10.10.11' # 在 pg-test 上运行,除了 10.10.10.11
查看 Ansible 文档中的所有详细信息:Patterns: targeting hosts and groups
谨慎运行没有主机限制的剧本!
在大多数时候,缺少这个值可能会有危险,因为大多数剧本将在 all 主机上执行。请谨慎使用 。
限制任务 执行任务 可以通过 -t|--tags <tags> 控制。
如果指定,将只执行具有给定标签的任务,而不是整个剧本。
./infra.yml -t repo # 创建仓库
./node.yml -t node_pkg # 安装节点包
./pgsql.yml -t pg_install # 安装 PG 包和扩展
./etcd.yml -t etcd_purge # 销毁 ETCD 集群
./minio.yml -t minio_alias # 写入 MinIO CLI 配置
要运行多个任务,指定多个标签并用逗号分隔 -t tag1,tag2:
./node.yml -t node_repo,node_pkg # 添加仓库,然后安装包
./pgsql.yml -t pg_hba,pg_reload # 配置,然后重新加载 pg hba 规则
额外变量 您可以使用 CLI 参数在运行时覆盖配置参数,它具有 最高优先级
额外的命令行参数可以通过 -e|--extra-vars KEY=VALUE 传递,可以多次使用:
# 使用另一个管理员用户创建管理员
./node.yml -e ansible_user = admin -k -K -t node_admin
# 初始化一个特定的 Redis 实例:10.10.10.11:6379
./redis.yml -l 10.10.10.10 -e redis_port = 6379 -t redis
# 删除 PostgreSQL,但保留软件包和数据
./pgsql-rm.yml -e pg_rm_pkg = false -e pg_rm_data = false
对于复杂参数,可以使用 JSON 字符串,一次传递多个复杂参数。
# 添加仓库并安装包
./node.yml -t node_install -e '{"node_repo_modules":"infra","node_packages":["duckdb"]}'
指定清单 默认配置文件是 Pigsty 主目录中的 pigsty.yml。
您可以使用 -i <path> 参数指定不同的 配置清单
./pgsql.yml -i conf/rich.yml # 根据 rich 配置初始化一个下载了所有扩展的单节点
./pgsql.yml -i conf/ha/full.yml # 根据 full 配置初始化一个 4 节点集群
./pgsql.yml -i conf/app/supa.yml # 根据 supa.yml 配置初始化一个 1 节点 Supabase 部署
便捷脚本 Pigsty 提供了一系列便捷脚本来简化常见操作,这些脚本位于 bin/ 目录下:
bin/node-add <cls> # 将节点纳入 Pigsty 管理:./node.yml -l <cls>
bin/node-rm <cls> # 从 Pigsty 移除节点:./node-rm.yml -l <cls>
bin/pgsql-add <cls> # 初始化 PG 集群:./pgsql.yml -l <cls>
bin/pgsql-rm <cls> # 移除 PG 集群:./pgsql-rm.yml -l <cls>
bin/pgsql-user <cls> <username> # 添加业务用户:./pgsql-user.yml -l <cls> -e username=<user>
bin/pgsql-db <cls> <dbname> # 添加业务数据库:./pgsql-db.yml -l <cls> -e dbname=<db>
bin/redis-add <cls> # 初始化 Redis 集群:./redis.yml -l <cls>
bin/redis-rm <cls> # 移除 Redis 集群:./redis-rm.yml -l <cls>
这些脚本是对 Ansible 剧本的简单封装,让您可以更方便地执行常见操作。
剧本列表 以下是 Pigsty 中的 内置剧本
6 - 离线安装 在没有互联网访问的环境中,使用离线安装包安装 Pigsty
Pigsty 默认从互联网上游 安装 离线软件包
概览 离线软件包 打包了所有需要的 RPM/DEB 软件包及其依赖;它是常规 安装
在 严肃的生产环境部署 强烈推荐 您使用离线安装包进行安装。
它可以确保后续所有新节点的软件版本与现有环境保持一致,
并且可以避免上游变动导致的在线安装失败(相当常见!)
确保您能独立自主运行它至地老天荒。
使用离线软件包的优点
可以简单方便的在互联网隔离的环境中交付实施。 一次性预下载所有软件包,可以有效加速安装过程。 无需担心上游依赖项的变动导致依赖错漏/安装失败。 如果有多个节点,那么所有软件包只需要下载一次,节省带宽资源。 可以通过本地仓库确保所有节点的软件版本一致,实行统一版本管理 使用离线软件包的缺点
离线安装包针对 特定的操作系统小版本制作 ,通常不能跨版本使用 仅为制作时刻的快照,可能不包含最新的更新和操作系统安全补丁。 离线安装包通常约 1GB 左右,而在线安装则是按需下载,更节省空间。 离线软件包 我们通常为以下 Linux 发行版
如果您使用的是上述列表中给出的操作系统(精确匹配的小版本),那么建议使用离线软件包。
Pigsty 为这些系统提供了开箱即用的预制离线软件包,在 GitHub 上提供免费下载。
您可以从 GitHub 发布页面
6a26fa44f90a16c7571d2aaf0e997d07 pigsty-v4.0.0.tgz
537839201c536a1211f0b794482d733b pigsty-pkg-v4.0.0.el9.x86_64.tgz
85687cb56517acc2dce14245452fdc05 pigsty-pkg-v4.0.0.el9.aarch64.tgz
a333e8eb34bf93f475c85a9652605139 pigsty-pkg-v4.0.0.el10.x86_64.tgz
4b98b463e2ebc104c35ddc94097e5265 pigsty-pkg-v4.0.0.el10.aarch64.tgz
4f62851c9d79a490d403f59deb4823f4 pigsty-pkg-v4.0.0.el8.x86_64.tgz
66e283c9f6bfa80654f7ed3ffb9b53e5 pigsty-pkg-v4.0.0.el8.aarch64.tgz
f7971d9d6aab1f8f307556c2f64b701c pigsty-pkg-v4.0.0.d12.x86_64.tgz
c4d870e5ef61ed05724c15fbccd1220b pigsty-pkg-v4.0.0.d12.aarch64.tgz
408991c5ff028b5c0a86fac804d64b93 pigsty-pkg-v4.0.0.d13.x86_64.tgz
8d7c9404b97a11066c00eb7fc1330181 pigsty-pkg-v4.0.0.d13.aarch64.tgz
2a25eff283332d9006854f36af6602b2 pigsty-pkg-v4.0.0.u24.x86_64.tgz
a4fb30148a2d363bbfd3bec0daa14ab6 pigsty-pkg-v4.0.0.u24.aarch64.tgz
87bb91ef703293b6ec5b77ae3bb33d54 pigsty-pkg-v4.0.0.u22.x86_64.tgz
5c81bdaa560dad4751840dec736fe404 pigsty-pkg-v4.0.0.u22.aarch64.tgz
离线软件包是为特定的 Linux 操作系统小版本制作的
当操作系统小版本不匹配时,有概率能用,也有概率失败,我们建议你不要冒险尝试。
请务必注意,Pigsty 提供的 EL9/EL10 安装包基于 9.6 / 10.0 制作,目前无法用于 9.7 / 10.1 小版本(因为 OpenSSL 版本发生变化)。
您需要在安装相同操作系统的环境中执行在线安装后制作离线安装包,或联系我们定制离线软件包。
使用离线软件包 离线安装的步骤 :
下载 Pigsty 离线软件包,将其放到 /tmp/pkg.tgz 下载 Pigsty 源码包,解压并进入目录(假设解压到家目录:cd ~/pigsty ./bootstrapansible./configure -g -c richrich照常运行 ./deploy.yml
如果您想要在自己的配置中,使用已经解包配置好的离线软件包,请修改并确保以下配置项:
repo_enabledtruenode_repo_moduleslocal在大部份模板中,此参数被显式配置为:node,infra,pgsql,即直接从这些上游软件仓库安装。 将其设置为 local,则会使用本地软件仓库安装所有软件包,速度最快,没有其他仓库的变数干扰。 如果你想同时使用本地软件仓库和上游软件仓库,可以将其设置为 local,node,infra,pgsql 第一个参数如果打开,Pigsty 会创建 本地软件仓库 ,第二个参数如果包含 local,则环境中的所有节点会使用这个本地软件仓库。
如果只包含 local,那么它会成为所有节点的唯一软件源,如果你还想要从其他上游软件仓库继续安装其他软件包,可以将其他仓库模块名称也添加进去,例如 local,node,infra,pgsql。
混合安装模式
如果您的环境有互联网访问,那么有一种混合方法可以融合离线安装与在线安装的优点。
您可以可以使用离线软件包作为基础,并在线补足不匹配的增量软件包。
例如,假设您使用的是 RockyLinux 9.5,但官方离线软件包是为 RockyLinux 9.6 制作的。
您可以使用 el9 离线软件包(虽然是针对 9.6 制作的),然后在执行正式安装前,执行 make repo-build 重新下载 9.5 对应的缺失软件包,
Pigsty 将从上游仓库重新下载所需的 增量 。
制作离线软件包 如果您选择的操作系统不在默认列表中,您可以使用内置的 cache.yml
找到一台运行完全相同操作系统版本,且可以访问互联网的节点 使用 rich在线安装 configure -c rich) cd ~/pigsty; ./cache.yml:制作并获取离线软件包到 ~/pigsty/dist/${version}/将离线软件包复制到没有互联网访问的环境中(ftp、scp、usb 等),通过 bootstrap 解包使用 我们提供 付费服务 ¥200 )。
Bootstrap Pigsty 依赖 ansible 执行剧本,这个脚本负责用各种方式来确保 ansible 正确安装。
./bootstrap # 确保 ansible 正确安装(如果有离线包,优先使用离线安装并解包使用)
通常在两种情况下,你需要运行这个脚本:
你不是通过 安装脚本 git clone 源码包的方式安装的,因此没有安装 ansible。 你准备通过离线软件包来安装 Pigsty,需要使用这个脚本来从离线软件包中安装 ansible。 bootstrap 脚本将自动检测离线软件包是否存在(-p 指定,默认为 /tmp/pkg.tgz)。
如果存在则解压使用它,然后从里面安装 ansible。
如果离线包不存在,它会尝试从互联网安装 ansible。如果还是不行,那你就要自己想办法了!
我的 yum/apt 仓库文件跑到哪里去了?
引导程序默认会 移走 现有软件源配置,以确保只有所需的仓库被启用。
您可以在 /etc/yum.repos.d/backup (EL) 或 /etc/apt/backup (Debian / Ubuntu) 中找回它们。
如果您想在 bootstrap 过程中保留现有软件源配置,请使用 -k|--keep 参数。
./bootstrap -k # 或 --keep
7 - 精简安装 只安装高可用 PostgreSQL 集群及其最小依赖的精简安装模式
如果您只想要高可用 PostgreSQL 数据库集群本身,而不需要监控、基础设施等功能,请考虑 精简安装 。
精简安装没有 INFRA本地仓库 ETCDPGSQLNODE
精简安装适合以下场景
只需要 PostgreSQL 数据库本身,不需要可观测性基础设施。 资源极度受限的环境,不愿意承担基础设施开销(单机约 0.2 vCPU / 500MB 开销) 已有外部监控系统,希望统一使用自己的监控管理体系。 不希望引入 AGPLv3 许可证的 Grafana 可视化看板组件。 精简安装的局限性
没有 基础设施模块 离线安装 概览 使用精简安装,您需要:
使用 slim.ymlconfigure -c slim) 执行 slim.yml 剧本进行部署,而不是默认的 deploy.yml curl https://repo.pigsty.cc/get | bash
./configure -g -c slim
./slim.yml
说明 精简安装只安装/配置以下组件:
组件 必要性 描述 patroni⚠️ 必需 引导高可用 PostgreSQL 集群 etcd⚠️ 必需 Patroni 的元数据库依赖(DCS) pgbouncer✔️ 可选 PostgreSQL 连接池 vip-manager✔️ 可选 L2 VIP 绑定到 PostgreSQL 集群主节点 haproxy✔️ 可选 根据 Patroni 健康检查,自动路由 服务 chronyd✔️ 可选 与 NTP 服务器的时间同步 tuned✔️ 可选 节点调优模板和内核参数管理
你可以通过进一步的配置,关闭所有可选组件,只保留必需组件 patroni 和 etcd。
因为缺少 Infra 模块的 Nginx 提供本地仓库服务,只有单机安装的时候可以进行离线安装
配置 精简安装的配置文件示例:conf/slim.yml
---
#==============================================================#
# File : slim.yml
# Desc : Pigsty slim installation config template
# Ctime : 2020-05-22
# Mtime : 2025-12-28
# Docs : https://doc.pgsty.com/config
# License : Apache-2.0 @ https://pigsty.io/docs/about/license/
# Copyright : 2018-2026 Ruohang Feng / Vonng ([email protected] )
#==============================================================#
# This is the config template for slim / minimal installation
# No monitoring & infra will be installed, just raw postgresql
#
# Usage:
# curl https://repo.pigsty.io/get | bash
# ./configure -c slim
# ./slim.yml
all :
children :
etcd : # dcs service for postgres/patroni ha consensus
hosts : # 1 node for testing, 3 or 5 for production
10.10.10.10 : { etcd_seq : 1 } # etcd_seq required
#10.10.10.11: { etcd_seq: 2 } # assign from 1 ~ n
#10.10.10.12: { etcd_seq: 3 } # odd number please
vars : # cluster level parameter override roles/etcd
etcd_cluster : etcd # mark etcd cluster name etcd
#----------------------------------------------#
# PostgreSQL Cluster
#----------------------------------------------#
pg-meta :
hosts :
10.10.10.10 : { pg_seq: 1, pg_role : primary }
#10.10.10.11: { pg_seq: 2, pg_role: replica } # you can add more!
#10.10.10.12: { pg_seq: 3, pg_role: replica, pg_offline_query: true }
vars :
pg_cluster : pg-meta
pg_users :
- { name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin ] ,comment : pigsty admin user }
- { name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly] ,comment : read-only viewer }
pg_databases :
- { name: meta, baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions : [ vector ]}
node_crontab : [ '00 01 * * * postgres /pg/bin/pg-backup full' ] # make a full backup every 1am
vars :
version : v4.0.0 # pigsty version string
admin_ip : 10.10.10.10 # admin node ip address
region: default # upstream mirror region : default,china,europe
nodename_overwrite : false # do not overwrite node hostname on single node mode
node_repo_modules : node,infra,pgsql # add these repos directly to the singleton node
node_tune: oltp # node tuning specs : oltp,olap,tiny,crit
pg_conf: oltp.yml # pgsql tuning specs : {oltp,olap,tiny,crit}.yml
pg_version : 18 # Default PostgreSQL Major Version is 18
pg_packages : [ pgsql-main, pgsql-common ] # pg kernel and common utils
#pg_extensions: [ pg18-time ,pg18-gis ,pg18-rag ,pg18-fts ,pg18-olap ,pg18-feat ,pg18-lang ,pg18-type ,pg18-util ,pg18-func ,pg18-admin ,pg18-stat ,pg18-sec ,pg18-fdw ,pg18-sim ,pg18-etl]
#----------------------------------------------#
# PASSWORD : https://doc.pgsty.com/config/security
#----------------------------------------------#
grafana_admin_password : pigsty
grafana_view_password : DBUser.Viewer
pg_admin_password : DBUser.DBA
pg_monitor_password : DBUser.Monitor
pg_replication_password : DBUser.Replicator
patroni_password : Patroni.API
haproxy_admin_password : pigsty
minio_secret_key : S3User.MinIO
etcd_root_password : Etcd.Root
... 部署 精简安装需要使用 slim.ymldeploy.yml
高可用集群 精简安装模式也可以部署高可用集群,在 etcd 和 pg-meta 分组中添加更多节点即可,一个三节点的部署样例:
ID NODE PGSQL INFRA ETCD 1 10.10.10.10pg-meta-1不安装基础设施模块 etcd-12 10.10.10.11pg-meta-2不安装基础设施模块 etcd-23 10.10.10.12pg-meta-3不安装基础设施模块 etcd-3
all :
children :
etcd :
hosts :
10.10.10.10 : { etcd_seq : 1 }
10.10.10.11 : { etcd_seq : 2 } # <-- 新增
10.10.10.12 : { etcd_seq : 3 } # <-- 新增
pg-meta :
hosts :
10.10.10.10 : { pg_seq: 1, pg_role : primary }
10.10.10.11 : { pg_seq: 2, pg_role : replica } # <-- 新增
10.10.10.12 : { pg_seq: 3, pg_role : replica } # <-- 新增
vars :
pg_cluster : pg-meta
pg_users :
- { name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin ] ,comment : pigsty admin user }
- { name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly] ,comment : read-only viewer }
pg_databases :
- { name: meta, baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions : [ vector ]}
node_crontab : [ '00 01 * * * postgres /pg/bin/pg-backup full' ] # make a full backup every 1am
vars :
# 省略 ……
8 - 安全建议 单机部署,快速上手时的三点安全加固建议
对于单机部署的 Demo/Dev 场景,只要您 修改了默认密码
如果您的部署对互联网开放,可以考虑添加 防火墙
除此之外,我们建议您保护好 Pigsty 的 关键文件
对于有着严格安全要求的企业级生产环境,请参考 部署-安全加固
密码 Pigsty 是一个开源项目,默认密码众所周知 。如果您的部署面向互联网或者办公网开放,请务必修改所有默认密码!
为了避免手动修改密码的繁琐,Pigsty 的 配置向导 提供了自动生成随机强密码的功能,使用 configure 的 -g 参数即可。
$ ./configure -g
configure pigsty v4.0.0 begin
[ OK ] region = china
[ WARN] kernel = Darwin, can be used as admin node only
[ OK ] machine = arm64
[ OK ] package = brew ( macOS)
[ WARN] primary_ip = default placeholder 10.10.10.10 ( macOS)
[ OK ] mode = meta ( unknown distro)
[ OK ] locale = C.UTF-8
[ OK ] generating random passwords...
grafana_admin_password : CdG0bDcfm3HFT9H2cvFuv9w7
pg_admin_password : 86WqSGdokjol7WAU9fUxY8IG
pg_monitor_password : 0X7PtgMmLxuCd2FveaaqBuX9
pg_replication_password : 4iAjjXgEY32hbRGVUMeFH460
patroni_password : DsD38QLTSq36xejzEbKwEqBK
haproxy_admin_password : uhdWhepXrQBrFeAhK9sCSUDo
minio_secret_key : z6zrYUN1SbdApQTmfRZlyWMT
etcd_root_password : Bmny8op1li1wKlzcaAmvPiWc
DBUser.Meta : U5v3CmeXICcMdhMNzP9JN3KY
DBUser.Viewer : 9cGQF1QMNCtV3KlDn44AEzpw
S3User.Backup : 2gjgSCFYNmDs5tOAiviCqM2X
S3User.Meta : XfqkAKY6lBtuDMJ2GZezA15T
S3User.Data : OygorcpCbV7DpDmqKe3G6UOj
[ OK ] random passwords generated, check and save them
[ OK ] ansible = ready
[ OK ] pigsty configured
[ WARN] don' t forget to check it and change passwords!
proceed with ./deploy.yml
防火墙 在互联网或者办公网开放的部署场景中,强烈建议配置 防火墙规则 ,限制访问 IP 范围与端口。
您可以使用云厂商提供的安全组功能,或者使用 Linux 发行版自带的防火墙服务(如 firewalld、ufw、iptables 等)来实现。
方向: 协议 端口 服务 说明 入站 TCP 22 SSH 允许 ssh 登陆管理 入站 TCP 80 Nginx 允许 Nginx HTTP 访问 入站 TCP 443 Nginx 允许 Nginx HTTPS 访问 入站 TCP 5432 PostgreSQL 远程公网访问数据库,按需启用
Pigsty 默认支持配置防火墙规则,允许 22/80/443/5432 从外部网络访问,但这并非默认启用。
文件 在 Pigsty 中,您需要特别保护以下文件:
pigsty.ymlfiles/pki/ca/ca.key我们建议您严格控制这两个文件的访问权限,并定期进行备份,将它们存储在一个安全的位置。