这是本节的多页打印视图。
点击此处打印 .
返回本页常规视图 .
概念 理解 Pigsty 的核心概念、架构设计与设计理念,掌握高可用、备份恢复、安全合规等关键能力。
Pigsty 是一个可移植、可扩展的开源 PostgreSQL 发行版,用于在本地环境中构建生产级数据库服务,方便进行声明式配置和自动化。它拥有庞大的生态系统,提供了一整套工具、脚本和最佳实践,让 PostgreSQL 真正达到企业级 RDS 的服务水准。
Pigsty 名字源自 P ostgreSQL I n G reat STY le,也可理解为 P ostgres, I nfras, G raphics, S ervice, T oolbox, it’s all Y ours —— 属于您的 PostgreSQL 图形化自建工具箱。您可以在 GitHub 官方文档 在线演示 Web 界面
为什么需要 Pigsty,它能做什么? PostgreSQL 是一个足够完美的数据库内核,但它需要更多工具与系统的配合才能成为一个足够好的数据库服务。在生产环境中,您需要管理数据库的方方面面:高可用、备份恢复、监控告警、访问控制、参数调优、扩展安装、连接池化、负载均衡……
如果这些复杂的运维工作都能自动化处理,是不是会更容易一些?这正是 Pigsty 诞生的原因。
Pigsty 为您提供:
开箱即用的 PostgreSQL 发行版
Pigsty 深度整合了 PostgreSQL 生态中的 440+ 扩展插件
故障自愈的高可用架构
基于 Patroni、Etcd 和 HAProxy 打造的 高可用架构
完整的时间点恢复能力
基于 pgBackRest 与可选的 MinIO 集群,提供开箱即用的 PITR 时间点恢复
灵活的服务接入与流量管理
通过 HAProxy、Pgbouncer、VIP 提供灵活的 服务接入
惊艳的可观测性
基于 Prometheus 与 Grafana 的现代可观测性技术栈,提供无与伦比的 监控最佳实践
声明式的配置管理
遵循 基础设施即代码
模块化的架构设计
采用模块化 架构
扎实的安全最佳实践
采用业界领先的安全最佳实践:自签名 CA 签发证书加密通信,AES 加密备份,scram-sha-256 加密密码,开箱即用的 ACL 模型,遵循最小权限原则的 HBA 规则集,确保数据安全。
简单易用的部署方案
所有依赖被预先打包,可在无互联网访问的环境中一键安装。本地沙箱环境可运行在 1核2G 的微型虚拟机中,提供与生产环境完全一致的功能模拟。提供基于 Vagrant 的本地沙箱与基于 Terraform 的云端部署方案。
Pigsty 不是什么 Pigsty 并不是传统的、包罗万象的 PaaS(平台即服务)系统。
Pigsty 不提供基础硬件资源 。它运行在您提供的节点之上,无论是裸金属、虚拟机还是云主机,但它本身不创建或管理这些资源(尽管提供了 Terraform 模板来简化云资源的准备)。
Pigsty 不是容器编排系统 。它直接运行在操作系统之上,不需要 Kubernetes 或 Docker 作为基础设施。当然,它可以与这些系统共存,并提供 Docker 模块来运行无状态应用。
Pigsty 不是通用的数据库管理工具 。它专注于 PostgreSQL 及其生态,虽然也支持 Redis、Etcd、MinIO 等周边组件,但核心始终是围绕 PostgreSQL 构建的。
Pigsty 不会锁定您 。它基于开源组件构建,不修改 PostgreSQL 内核,不引入专有协议。您随时可以脱离 Pigsty 继续使用管理好的 PostgreSQL 集群。
Pigsty 不限制您应该或不应该如何构建数据库服务。例如:
Pigsty 为您提供了良好的参数默认值和配置模板,但您可以覆盖任何参数。 Pigsty 提供了声明式 API,但您依然可以使用底层工具(Ansible、Patroni、pgBackRest 等)进行手动管理。 Pigsty 可以管理完整的生命周期,也可以只使用其中的监控系统来观测现有的数据库实例或 RDS。 Pigsty 提供的抽象层次不同于硬件层面,它工作在数据库服务层面,聚焦于如何让 PostgreSQL 以最佳状态交付价值,而不是重新发明轮子。
PostgreSQL 部署方式的演进 要理解 Pigsty 的价值,让我们回顾一下 PostgreSQL 部署方式的演进历程。
手工部署时代 在传统的部署方式中,DBA 需要手工安装配置 PostgreSQL,手工设置复制,手工配置监控,手工处理故障。这种方式的问题显而易见:
效率低下 :每个实例都需要重复大量手工操作,容易出错。缺乏标准化 :不同 DBA 配置的数据库可能千差万别,难以维护。可靠性差 :故障处理依赖人工介入,恢复时间长,容易出现人为失误。观测性弱 :缺乏统一的监控体系,问题发现和定位困难。托管数据库时代 为了解决这些问题,云厂商提供了托管数据库服务(RDS)。云 RDS 确实解决了部分运维问题,但也带来了新的挑战:
成本高昂 :托管服务通常收取硬件成本数倍到十几倍的"服务费"。供应商锁定 :迁移困难,受制于特定云平台。功能受限 :无法使用某些高级特性,扩展插件受限,参数调整受限。数据主权 :数据存储在云端,自主可控性降低。本地 RDS 时代 Pigsty 代表了第三种方式:在本地环境中构建媲美甚至超越云 RDS 的数据库服务。
Pigsty 结合了前两种方式的优点:
自动化程度高 :一键部署,自动配置,故障自愈,像云 RDS 一样便捷。完全自主可控 :运行在您自己的基础设施上,数据完全掌握在自己手中。成本极低 :以接近纯硬件的成本运行企业级数据库服务。功能完整 :无限制地使用 PostgreSQL 的全部能力和生态扩展。开放架构 :基于开源组件,无供应商锁定,可随时迁移。这种方式特别适合:
私有云与混合云 :需要在本地环境中运行数据库的企业。成本敏感型用户 :希望降低数据库 TCO 的组织。高安全要求场景 :需要完全自主可控的关键数据。PostgreSQL 深度用户 :需要使用高级特性和丰富扩展的场景。开发与测试 :需要在本地快速搭建与生产环境一致的数据库。接下来 现在您已经了解了 Pigsty 的基本概念,可以:
查看 系统架构 了解 集群模型 学习 高可用 探索 时间点恢复 研究 服务接入 体验 基础设施即代码 或直接开始 快速上手 1 - 模块化架构 Pigsty 的模块化架构介绍 —— 声明式组合,按需定制,自由部署。
Pigsty 使用 模块化架构 与 声明式接口 ,您可以像 搭积木一样自由按需组合模块
模块 Pigsty 采用模块化设计,有六个主要的默认模块:PGSQLINFRANODEETCDREDISMINIO
PGSQLINFRANODEETCDREDISMINIO你可以声明式地自由组合它们。如果你想要主机监控,在基础设施节点上安装INFRANODEETCDPGSQLREDISMINIO
请注意,所有模块都强依赖 NODE 模块:在 Pigsty 中节点必须先安装 NODE 模块,被 Pigsty 纳管后方可部署其他模块。
当节点(默认)使用本地软件源进行安装时,NODE 模块对 INFRA 模块有弱依赖。因此安装 INFRA 模块的管理节点/基础设施节点会在 deploy.yml
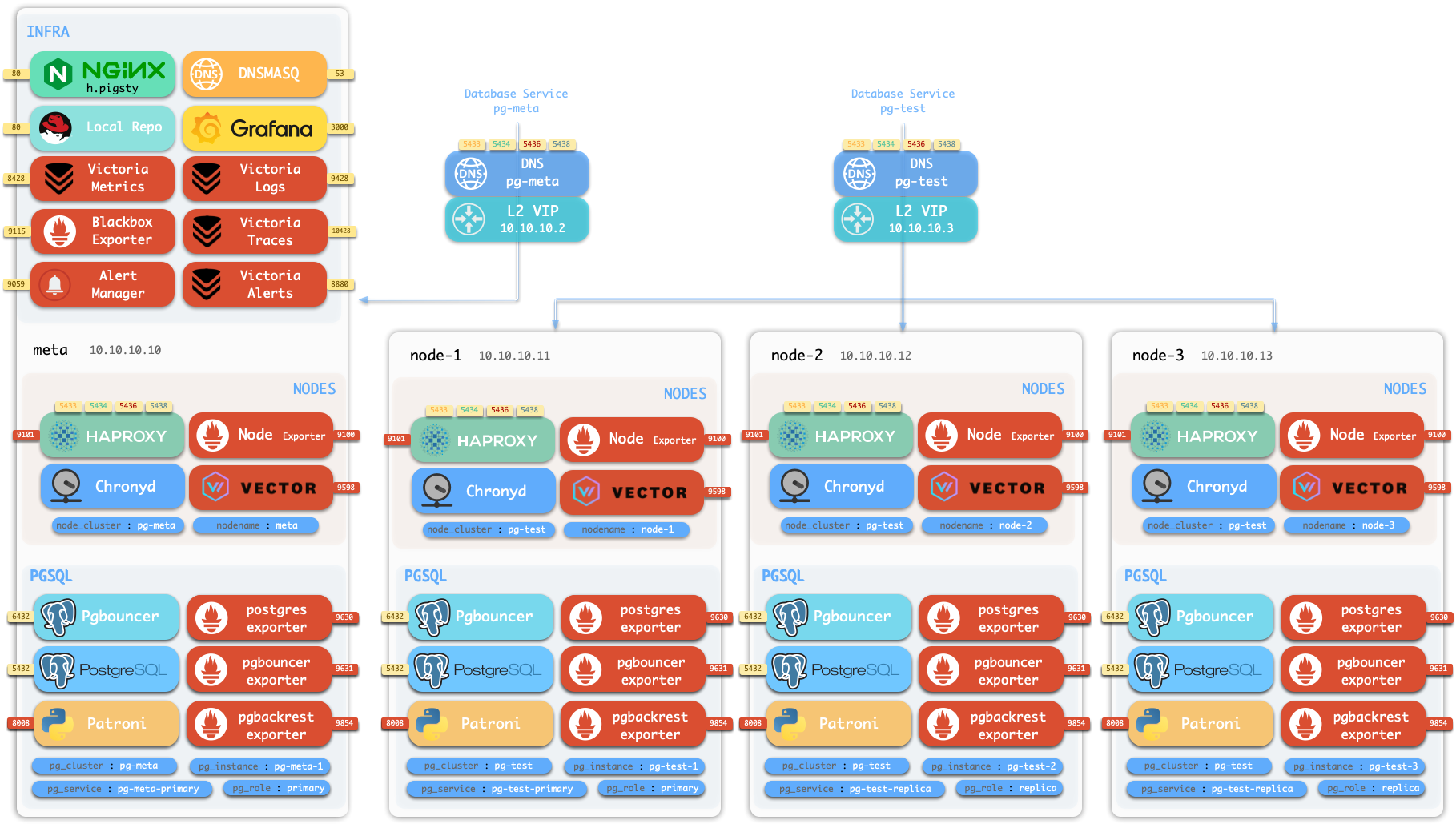
单机安装 默认情况下,Pigsty 将在单个 节点 (物理机/虚拟机) 上安装。deploy.yml当前 节点上安装 INFRAETCDPGSQLMINIOpg-meta,库名为 meta)。
这个节点现在会有完整的自我监控系统、可视化工具集,以及一个自动配置有 PITR 的 Postgres 数据库(HA不可用,因为你只有一个节点)。你可以使用此节点作为开发箱、测试、运行演示以及进行数据可视化和分析。或者,还可以把这个节点当作管理节点,部署纳管更多的节点!
监控 安装的 单机元节点 可用作管理节点 和监控中心 ,以将更多节点和数据库服务器置于其监视和控制之下。
Pigsty 的监控系统可以独立使用,如果你想安装 Prometheus / Grafana 可观测性全家桶,Pigsty 为你提供了最佳实践!
它为 主机节点 和 PostgreSQL数据库 提供了丰富的仪表盘。
无论这些节点或 PostgreSQL 服务器是否由 Pigsty 管理,只需简单的配置,你就可以立即拥有生产级的监控和告警系统,并将现有的主机与PostgreSQL纳入监管。
高可用PG集群 Pigsty 帮助您在任何地方 拥有 您自己的生产级高可用 PostgreSQL RDS 服务。
要创建这样一个高可用 PostgreSQL 集群/RDS服务,你只需用简短的配置来描述它,并运行剧本来创建即可:
pg-test :
hosts :
10.10.10.11 : { pg_seq: 1, pg_role : primary }
10.10.10.12 : { pg_seq: 2, pg_role : replica }
10.10.10.13 : { pg_seq: 3, pg_role : replica }
vars : { pg_cluster : pg-test }
$ bin/pgsql-add pg-test # 初始化集群 'pg-test'
不到10分钟,您将拥有一个服务接入,监控,备份PITR,高可用配置齐全的 PostgreSQL 数据库集群。
硬件故障由 patroni、etcd 和 haproxy 提供的自愈高可用架构来兜底,在主库故障的情况下,默认会在 30 秒内执行自动故障转移(Failover)。
客户端无需修改配置重启应用:Haproxy 利用 patroni 健康检查进行流量分发,读写请求会自动分发到新的集群主库中,并避免脑裂的问题。
这一过程十分丝滑,例如在从库故障,或主动切换(switchover)的情况下,客户端只有一瞬间的当前查询闪断,
软件故障、人为错误和 数据中心级灾难由 pgbackrest 和可选的 MinIO 集群来兜底。这为您提供了本地/云端的 PITR 能力,并在数据中心失效的情况下提供了跨地理区域复制,与异地容灾功能。
1.1 - 节点 节点(node)是对硬件资源/操作系统的抽象,可以是物理机,裸金属、虚拟机、或者容器与 pods。
节点(node) 是对硬件资源/操作系统的抽象,可以是物理机,裸金属、虚拟机、或者容器与 pods。
只要装着 Linux 操作系统(以及 systemd 守护进程),能使用 CPU/内存/磁盘/网络 等标准资源,即可视作节点。
节点上可以安装 模块
在 单机部署
普通节点 使用 Pigsty 管理节点,可在其上安装模块。node.yml
组件 端口 描述 状态 node_exporter9100节点监控指标导出器 ✅ 默认启用 haproxy9101HAProxy 负载均衡器(管理端口) ✅ 默认启用 vector9598日志收集代理 ✅ 默认启用 docker9323启用容器支持 ⚠️ 按需启用 keepalivedn/a管理节点集群 L2 VIP ⚠️ 按需启用 keepalived_exporter9650监控 Keepalived 状态 ⚠️ 按需启用
这里,node_exporter 会向监控系统暴露主机上的各类监控指标,vector 会向日志收集系统发送日志,haproxy 则提供负载均衡功能,对外暴露服务。
这三项服务默认开启。而 Docker keepalived 及 keepalived_exporter 这三项服务作为可选项,可按需启用。
ADMIN节点 一套 Pigsty 部署中有且只有一个 管理节点 ,管理节点是执行 Ansible 剧本,发起控制/部署命令的节点。
该节点拥有对所有其他节点的 ssh/sudo 访问权限。管理节点的安全至关重要,请确保它的访问受到严格控制。
在 单机安装 配置过程
例如,您使用自己的笔记本电脑,管理一台云端上部署了 Pigsty 的虚拟机,这时候,您的笔记本电脑就是管理节点。
在严肃的生产环境中,管理节点通常是 1-2 台 DBA 专用的 管控机 。在资源受限的环境中,则通常会复用 INFRA节点
INFRA节点 一套 Pigsty 部署可能有 1 个或多个 INFRA 节点,大型生产环境可能有 2-3 个。
配置清单中的 infraINFRA
组件 端口 描述 nginx80/443Web 图形界面,本地软件仓库 grafana3000可视化平台 victoriaMetrics8428时序数据库(收存监控指标) victoriaLogs9428日志收集服务器 victoriaTraces10428链路追踪收集服务器 vmalert8880告警与衍生指标计算规则 alertmanager9093告警聚合分发/屏蔽管理 blackbox_exporter9115黑盒探测,ping 节点 / vip dnsmasq53内部 DNS 域名解析 chronyd123NTP 时间服务器 ansible-执行剧本,发起管理
其中,Nginx 作为当前模块的入口,提供 Web 图形界面和本地软件仓库服务。
如果你部署多个 INFRA 节点,每个 Infra 节点上的服务是相互独立的。
但你确实可以从任意一个 Infra 节点上的 Grafana 访问所有的监控数据源。
请注意,INFRA AGPLv3 Apache-2.0
ETCD节点 ETCD
配置清单 etcd
组件 端口 描述 etcd2379ETCD 分布式键值存储(客户端端口) etcd2380ETCD 集群 Peer 通信端口
MINIO节点 MINIOn 备份存储仓库
配置清单中的 minio
组件 端口 描述 minio9000MinIO S3 API 服务端口 minio9001MinIO 管理控制台端口
PGSQL节点 安装了 PGSQL
PGSQL 节点可从相应 PostgreSQL 实例借用 身份 —— 由 node_id_from_pgtrue,即节点名会被设置为 PG 实例名。
PGSQL节点在 普通节点
组件 端口 描述 状态 postgres5432PostgreSQL 数据库服务器 ✅ 默认启用 pgbouncer6432Pgbouncer 连接池 ✅ 默认启用 patroni8008Patroni 高可用管理组件 ✅ 默认启用 pg_exporter9630Postgres 监控指标导出器 ✅ 默认启用 pgbouncer_exporter9631PGBouncer 监控指标导出器 ✅ 默认启用 pgbackrest_exporter9854Pgbackrest 监控指标导出器 ✅ 默认启用 vip-managern/a将 L2 VIP 绑定在集群主库节点上 ⚠️ 按需启用 {{ pg_cluster }}-primary5433通过 haproxy 对外暴露数据库服务:主连接池:读/写服务 ✅ 默认启用 {{ pg_cluster }}-replica5434通过 haproxy 对外暴露数据库服务:副本连接池:只读服务 ✅ 默认启用 {{ pg_cluster }}-default5436通过 haproxy 对外暴露数据库服务:主直连服务 ✅ 默认启用 {{ pg_cluster }}-offline5438通过 haproxy 对外暴露数据库服务:离线直连:离线读服务 ✅ 默认启用 {{ pg_cluster }}-<service>543x通过 haproxy 对外暴露数据库服务:PostgreSQL 定制服务 ⚠️按需定制
其中,vip-manager 只有当用户配置了 PG VIP 时才会启用。
在 pg_services自定义服务 haproxy 对外暴露,并使用更多的服务端口。
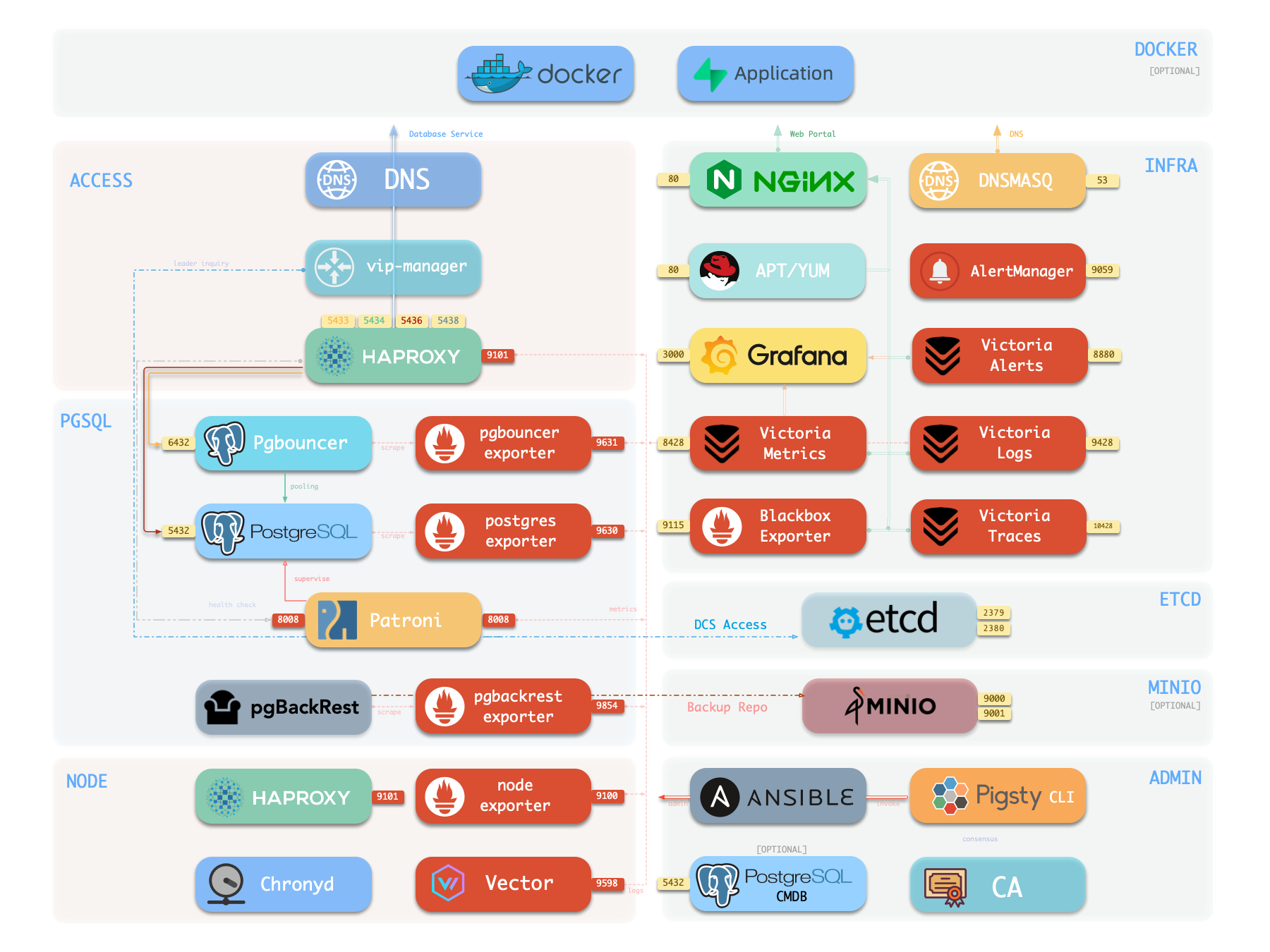
1.2 - INFRA 架构 Pigsty 中基础设施模块的架构,组件与功能详解。
运行生产级别高可用 PostgreSQL 集群,通常需要一套完善的基础设施服务(底座)来支撑,例如监控告警、日志收集、时间同步、DNS 解析,本地软件仓库等。
Pigsty 提供了 INFRA 模块 可选模块 ,但我们强烈推荐启用它。
概览 下图是 单机部署 INFRA 模块
Nginx Nginx 是 Pigsty 所有 WebUI 类服务的访问入口,默认使用 80443在线演示
带有 WebUI 的基础设施组件可以通过 Nginx 统一对外暴露服务,例如 Grafana 、VictoriaMetrics (VMUI)、AlertManager ,
以及 HAProxy 控制台,此外,本地软件仓库 等静态文件资源也通过 Nginx 对内外提供服务。
Nginx 会根据 infra_portal
infra_portal :
home : { domain : i.pigsty }
默认情况下将对外暴露 Pigsty 的管理首页:i.pigsty,上面不同的端点挂载代理了不同的组件:
Pigsty 允许对 Nginx 进行丰富的定制,将其作为本地文件服务器,或者反向代理服务器,配置自签名或者真正的 HTTPS 证书。
更多信息,请参阅:教程:Nginx:向外代理暴露Web服务 教程:Certbot:申请与更新HTTPS证书
Repo Pigsty 会在安装时,默认在 Infra 节点上创建一个 本地软件仓库 ,以加速后续软件安装。在线演示
该软件仓库默认位于 /www/pigstyNginx 对外提供服务,挂载在 /pigsty 路径上:
Pigsty 支持 离线安装 /www/pigsty/repo_complete
更多信息,请参阅:配置:INFRA - REPO
Grafana Grafana 是 Pigsty 监控系统的核心组件,用于可视化展示监控指标、日志与各种信息。在线演示
Grafana 默认监听 3000 端口,挂载于 Nginx /ui 路径点上代理访问:
Pigsty 预置了基于 VictoriaMetrics / Logs / Traces 的大量监控面板,并通过 URL 跳转实现一键下钻上卷,帮助快速定位故障。
Grafana 亦可作为低代码可视化平台使用,因此默认安装 ECharts 、victoriametrics-datasource、victorialogs-datasource 等插件,
同时将 Vector / Victoria 数据源统一注册为 vmetrics-*、vlogs-*、vtraces-*,方便扩展自定义仪表板。
更多信息请参阅:配置:INFRA - GRAFANA
VictoriaMetrics VictoriaMetrics 是 Pigsty 的时序数据库,负责拉取并存储所有监控指标。在线演示
默认监听 8428 端口,挂载于 Nginx /vmetrics 路径上,亦可通过 p.pigsty 域名直接访问:
VictoriaMetrics 完全兼容 Prometheus API,支持 PromQL 查询、远程读写协议以及 Alertmanager API。
内置的 VMUI 提供即席查询界面,可直接探索指标数据,也可作为 Grafana 的数据源使用。
更多信息请参阅:配置:INFRA - VICTORIA
VictoriaLogs VictoriaLogs 是 Pigsty 的日志平台,集中存储来自所有节点的结构化日志。在线演示
默认监听 9428 端口,挂载于 Nginx /vlogs 路径上:
所有纳管节点默认运行 Vector Agent,负责收集系统日志、PostgreSQL 日志、Patroni 日志、Pgbouncer 日志等,结构化处理后推送至 VictoriaLogs 。
内置 Web UI 支持日志检索与过滤,也可配合 Grafana 的 victorialogs-datasource 插件进行可视化分析。
更多信息请参阅:配置:INFRA - VICTORIA
VictoriaTraces VictoriaTraces 用于收集链路追踪数据与慢 SQL 记录。在线演示
默认监听 10428 端口,挂载于 Nginx /vtraces 路径上:
VictoriaTraces 提供 Jaeger 兼容接口,可用于分析服务调用链路与数据库慢查询。
结合 Grafana 面板,能够快速定位性能瓶颈,追溯问题根因。
更多信息请参阅:配置:INFRA - VICTORIA
VMAlert VMAlert 是告警规则计算引擎,负责评估告警规则并将触发的事件推送至 Alertmanager 。在线演示
默认监听 8880 端口,挂载于 Nginx /vmalert 路径上:
VMAlert 从 VictoriaMetrics 读取指标数据,周期性执行告警规则评估。
Pigsty 预置了 PGSQL、NODE、REDIS 等模块的告警规则,覆盖常见故障场景,开箱即用。
更多信息请参阅:配置:INFRA - PROMETHEUS
AlertManager AlertManager 负责告警事件的聚合、去重、分组与分发。在线演示
默认监听 9059 端口,挂载于 Nginx /alertmgr 路径上,亦可通过 a.pigsty 域名直接访问:
AlertManager 支持多种通知渠道:邮件、Webhook、Slack、PagerDuty、企业微信等。
通过配置告警路由规则,可实现按严重程度、模块类型进行差异化分发,支持静默、抑制等高级功能。
更多信息请参阅:配置:INFRA - PROMETHEUS
BlackboxExporter Blackbox Exporter 用于主动探测目标的可达性,实现黑盒监控。
默认监听 9115 端口,挂载于 Nginx /blackbox 路径上:
支持 ICMP Ping、TCP 端口、HTTP/HTTPS 端点等多种探测方式。
可用于监控 VIP 可达性、服务端口存活、外部依赖健康状态等场景,是判断故障影响范围的重要手段。
更多信息请参阅:配置:INFRA - PROMETHEUS
Ansible Ansible 是 Pigsty 的核心编排工具,所有部署、配置、管理操作均通过 Ansible Playbook 完成。
Pigsty 在安装时会自动在管理节点(Infra 节点)上安装 Ansible 。
它采用声明式配置风格与幂等剧本设计:同一剧本可重复执行,系统会自动收敛至期望状态,无需担心副作用。
Ansible 的核心优势:
无 Agent :通过 SSH 远程执行,无需在目标节点安装额外软件。声明式 :描述期望状态,而非执行步骤,配置即文档。幂等性 :多次执行结果一致,支持部分失败后重试。更多信息请参阅:剧本:Pigsty Playbook
DNSMASQ DNSMASQ 提供环境内的 DNS 解析服务,将 Pigsty 内部使用的域名解析到对应 IP 地址。
请注意,DNS 是完全可选的模块,Pigsty 本身不依赖 DNS 即可正常运行。
默认监听 53 端口(UDP/TCP),为环境内所有节点提供 DNS 解析:
协议 端口 配置文件目录 UDP/TCP 53/infra/hosts/
其他模块在部署时会自动将域名注册到 INFRA 节点的 DNSMASQ 服务中,例如:
客户端节点可将 INFRA 节点配置为 DNS 服务器,即可通过域名访问各服务,无需记忆 IP 地址。
更多信息请参阅:配置:INFRA - DNS 教程:DNS:配置域名解析
Chronyd Chronyd 提供 NTP 时间同步服务,确保环境内所有节点时钟一致。
默认监听 123 端口(UDP),作为环境内的时间源:
时间同步对分布式系统至关重要:日志排查需要时间戳对齐,证书校验依赖时钟准确,PostgreSQL 流复制也对时钟偏移敏感。
在隔离网络环境中,INFRA 节点可作为内部 NTP 服务器,其他节点同步至此。
更多信息请参阅:配置:NODE - NTP
节点与Infra的关系 节点关系 普通的节点,会通过 admin_ipINFRA节点
例如,当你配置了全局的 admin_ip = 10.10.10.10,那么通常意味着所有节点都会使用这个 IP 上的基础设施服务。
以下是引用 ${admin_ip} 的配置参数列表
这是一种弱依赖关系
通常管理节点与基础设施节点(INFRA 节点)重合。若有多个 INFRA 节点,管理节点通常是其中第一个,其他作为备份。
在大规模生产环境部署的时候,您可能会出于各种原因,将安装 Ansible 管理节点与运行 Infra 模块的节点分离开来。
例如,使用 1-2 台迷你的专用主机,归属于 DBA 组,作为整个环境的控制中枢,ADMIN 节点。
使用 2-3 台高配置的物理机,作为整个环境的监控基础设施 INFRA 节点。
下表展示了不同规模部署中各类节点的典型数量:
部署规模 ADMIN INFRA ETCD MINIO PGSQL 单机开发 1 1 1 0 1 三节点 1 3 3 0 3 小型生产 1 2 3 0 N 大型生产 2 3 5 4+ N
1.3 - PGSQL 架构 PostgreSQL 模块的组件交互与数据流。
PGSQL 模块在生产环境中以 集群 的形式组织,这些 集群 是由一组通过 主-备 关联的数据库 实例 组成的 逻辑实体 。
每个集群都是一个 自治 的业务单元,由至少一个 主库实例 组成,并通过服务向外暴露能力。
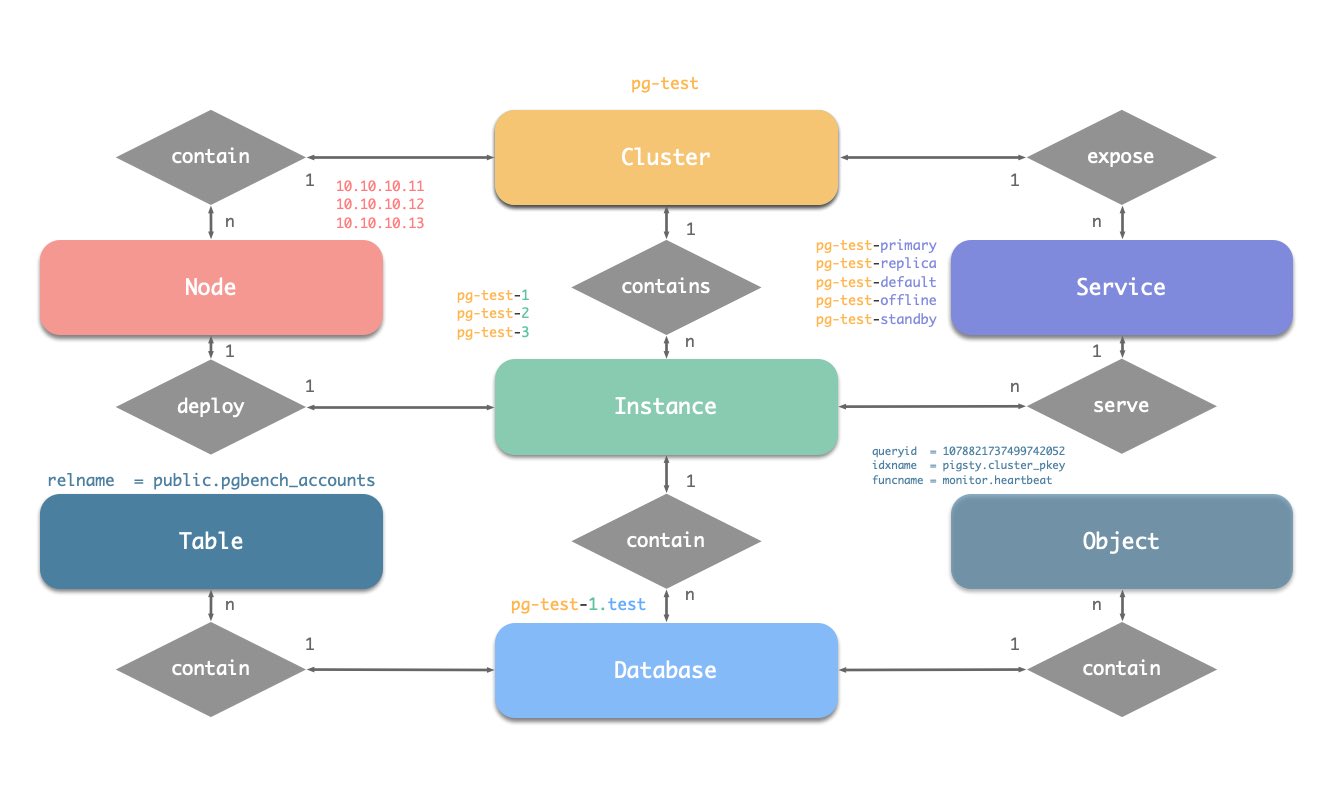
在 Pigsty 的 PGSQL 模块中有四种核心实体:
集群 (Cluster):自治的 PostgreSQL 业务单元,用作其他实体的顶级命名空间。服务 (Service):对外暴露能力的命名抽象,路由流量,并使用节点端口暴露服务。实例 (Instance):由在单个节点上的运行进程和数据库文件组成的单一 PostgreSQL 服务器。节点 (Node):运行 Linux + Systemd 环境的硬件资源抽象,可以是裸机、VM、容器或 Pod。辅以"数据库"“角色"两个业务实体,共同组成完整的逻辑视图。如下图所示:
命名约定
集群名应为有效的 DNS 域名,不包含任何点号,正则表达式为:[a-zA-Z0-9-]+ 服务名应以集群名为前缀,并以特定单词作为后缀:primary、replica、offline、delayed,中间用 - 连接。 实例名以集群名为前缀,以正整数实例号为后缀,用 - 连接,例如 ${cluster}-${seq}。 节点由其首要内网 IP 地址标识,因为 PGSQL 模块中数据库与主机 1:1 部署,所以主机名通常与实例名相同。 概览 下图是 PGSQL 模块的架构示意图,展示了各组件之间的交互关系:
PostgreSQL PostgreSQL 是 PGSQL 模块的核心,默认监听 5432 端口提供关系型数据库服务。
协议 端口 说明 TCP 5432PostgreSQL 数据库服务端口
在多个节点上以相同 pg_clusterpg_roleprimary(主库)、replica(从库)、offline(离线从库)。
PostgreSQL 进程默认由 Patroni 托管,可根据 pg_confpg_parameters
更多信息请参阅:配置:PGSQL - PG_BOOTSTRAP
Patroni Patroni 是 PostgreSQL 高可用控制器,默认监听 8008 端口提供 REST API。
协议 端口 说明 TCP 8008Patroni REST API / 健康检查
Patroni 接管 PostgreSQL 的启动、停止、配置与健康状态,将领导者、成员信息写入 etcd 。
它负责自动故障转移、保持复制因子、协调参数变更,并提供 REST API 供 HAProxy 、监控与管理员查询。
HAProxy 通过 Patroni 健康检查端点判断实例角色,将流量路由至正确的主库或从库。
vip-manager 监视 etcd 中的领导者键,在主库切换时自动漂移 VIP。
更多信息请参阅:配置:PGSQL - PG_BOOTSTRAP
Pgbouncer Pgbouncer 是轻量级连接池中间件,默认监听 6432 端口。
协议 端口 说明 TCP 6432Pgbouncer 连接池端口
Pgbouncer 以无状态方式运行在每个实例上,通过本地 Unix Socket 连接 PostgreSQL ,
用于吸收瞬时连接、稳定会话并提供额外指标。
Pigsty 默认让生产流量(读写服务 5433 / 只读服务 5434)经由 Pgbouncer ,
仅默认服务(5436)与离线服务(5438)绕过连接池直连 PostgreSQL 。
连接池模式由 pgbouncer_poolmodetransaction(事务级复用)。
可通过 pgbouncer_enabled
更多信息请参阅:配置:PGSQL - PG_ACCESS
HAProxy HAProxy 是服务入口与负载均衡器,对外暴露多个数据库服务端口。
端口 服务名 目标 说明 9101管理接口 - HAProxy 统计与管理页面 5433primary 主库 Pgbouncer 读写服务,路由至主库连接池 5434replica 从库 Pgbouncer 只读服务,路由至从库连接池 5436default 主库 Postgres 默认服务,直连主库(绕过连接池) 5438offline 离线库 Postgres 离线服务,直连离线从库(ETL/分析)
HAProxy 通过 Patroni REST API 提供的健康检查信息判断实例角色,将流量路由至对应的主库或从库。
服务定义由 pg_default_servicespg_services
可通过 pg_service_providerHAProxy 对外发布服务。
更多信息请参阅:服务接入 配置:PGSQL - PG_ACCESS
vip-manager vip-manager 负责将 L2 VIP 绑定到当前主库节点,实现透明漂移。
vip-manager 在每个 PG 节点上运行,监视 etcd 中由 Patroni 写入的领导者键,
将 pg_vip_address
当发生故障转移时,vip-manager 会立即释放旧主机上的 VIP,并在新主机上重新绑定,
保障旧主机不会继续响应请求,避免脑裂。
该组件可选,通过 pg_vip_enabled
更多信息请参阅:教程:VIP 配置 配置:PGSQL - PG_ACCESS
pgBackRest pgBackRest 是专业的 PostgreSQL 备份恢复工具,支持全量/增量/差异备份与 WAL 归档。
功能 说明 全量备份 完整数据库备份 增量备份 仅备份变化的数据块 WAL归档 持续归档 WAL 日志,支持 PITR 仓库 本地磁盘(默认)或 MinIO 等对象存储
pgBackRest 与 PostgreSQL 配合,在主库上创建备份仓库,执行备份与归档任务。
默认使用本地备份仓库(pgbackrest_methodlocal),
也可配置为 MinIO 等对象存储,实现集中化备份管理。
初始化完成后可通过 pgbackrest_init_backupPatroni 集成,支持将副本引导为新的主库或备库。
更多信息请参阅:备份恢复 配置:PGSQL - PG_BACKUP
pg_exporter pg_exporter 导出 PostgreSQL 监控指标,默认监听 9630 端口。
协议 端口 说明 TCP 9630pg_exporter 指标端口
pg_exporter 运行在每个 PG 节点上,通过本地 Unix Socket 连接 PostgreSQL ,
导出覆盖会话、缓冲命中、复制延迟、事务率等丰富指标,供 INFRA 节点上的 VictoriaMetrics 抓取。
采集配置由 pg_exporter_configpg_exporter_auto_discoverypg_exporter_cache_ttls
更多信息请参阅:配置:PGSQL - PG_MONITOR
pgbouncer_exporter pgbouncer_exporter 导出 Pgbouncer 连接池指标,默认监听 9631 端口。
协议 端口 说明 TCP 9631pgbouncer_exporter 指标端口
pgbouncer_exporter 读取 Pgbouncer 的统计视图,提供连接池利用率、等待队列与命中率指标。
若禁用 Pgbouncer ,本组件也应同时关闭。
更多信息请参阅:配置:PGSQL - PG_MONITOR
pgbackrest_exporter pgbackrest_exporter 导出备份状态指标,默认监听 9854 端口。
协议 端口 说明 TCP 9854pgbackrest_exporter 指标端口
pgbackrest_exporter 解析 pgBackRest 状态,生成最近备份时间、大小、类型等指标。
结合告警策略可快速发现备份过期或失败,保障数据安全。
更多信息请参阅:配置:PGSQL - PG_MONITOR
总结 PGSQL 模块为 Pigsty 提供生产级 PostgreSQL 高可用集群,是整个系统的核心。
组件 端口 说明 PostgreSQL 5432数据库服务 Patroni 8008高可用控制器 REST API Pgbouncer 6432连接池 HAProxy 543x服务入口与负载均衡 vip-manager - L2 VIP 管理(可选) pgBackRest - 备份恢复 pg_exporter 9630PostgreSQL 指标导出 pgbouncer_exporter 9631Pgbouncer 指标导出 pgbackrest_exporter 9854备份状态指标导出
典型的访问路径:客户端 → DNS/VIP → HAProxy(服务端口) → Pgbouncer → PostgreSQL。
Patroni 与 etcd 协同实现自动故障转移,pgBackRest 保障数据可恢复,
三个 Exporter 配合 VictoriaMetrics 提供完整的可观测性。
更多信息请参阅:PGSQL 模块 组件与交互
2 - 集群概念图 Pigsty 是如何将不同种类的功能抽象成为模块的,以及这些模块的逻辑模型。
在 Pigsty 中,功能模块是以 “集群” 的方式组织起来的。每一个集群都是一个 Ansible 分组,包含有若干节点资源,定义有实例
PGSQL 模块总览:关键概念与架构细节
PGSQL模块在生产环境中以集群 的形式组织,这些集群 是由一组由主-备 关联的数据库实例 组成的逻辑实体 。
每个数据库集群 都是一个自治 的业务服务单元,由至少一个 数据库(主库)实例 组成。
实体概念图 让我们从ER图开始。在Pigsty的PGSQL模块中,有四种核心实体:
集群 (Cluster):自治的PostgreSQL业务单元,用作其他实体的顶级命名空间。服务 (Service):集群能力的命名抽象,路由流量,并使用节点端口暴露postgres服务。实例 (Instance):一个在单个节点上的运行进程和数据库文件组成的单一postgres服务器。节点 (Node):硬件资源的抽象,可以是裸金属、虚拟机或甚至是k8s pods。
命名约定
集群名应为有效的 DNS 域名,不包含任何点号,正则表达式为:[a-zA-Z0-9-]+ 服务名应以集群名为前缀,并以特定单词作为后缀:primary、replica、offline、delayed,中间用-连接。 实例名以集群名为前缀,以正整数实例号为后缀,用-连接,例如${cluster}-${seq}。 节点由其首要内网IP地址标识,因为PGSQL模块中数据库与主机1:1部署,所以主机名通常与实例名相同。 身份参数 Pigsty使用身份参数 来识别实体:PG_ID
除了节点IP地址,pg_clusterpg_rolepg_seq沙箱环境 测试集群pg-test为例:
pg-test :
hosts :
10.10.10.11 : { pg_seq: 1, pg_role : primary }
10.10.10.12 : { pg_seq: 2, pg_role : replica }
10.10.10.13 : { pg_seq: 3, pg_role : replica }
vars :
pg_cluster : pg-test
集群的三个成员如下所示:
集群 序号 角色 主机 / IP 实例 服务 节点名 pg-test1primary10.10.10.11pg-test-1pg-test-primarypg-test-1pg-test2replica10.10.10.12pg-test-2pg-test-replicapg-test-2pg-test3replica10.10.10.13pg-test-3pg-test-replicapg-test-3
这里包含了:
一个集群:该集群命名为pg-test。 两种角色:primary和replica。 三个实例:集群由三个实例组成:pg-test-1、pg-test-2、pg-test-3。 三个节点:集群部署在三个节点上:10.10.10.11、10.10.10.12和10.10.10.13。 四个服务: 在监控系统(Prometheus/Grafana/Loki)中,相应的指标将会使用这些身份参数进行标记:
pg_up{cls="pg-meta", ins="pg-meta-1", ip="10.10.10.10", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-1", ip="10.10.10.11", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-2", ip="10.10.10.12", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-3", ip="10.10.10.13", job="pgsql"}
3 - 声明式配置 —— 基础设施即代码(IaC) Pigsty 使用基础设施即代码(IaC)的理念管理所有组件,针对大规模集群提供声明式管理能力。
Pigsty 遵循 IaC 与 GitOPS 的理念:使用声明式的 配置清单 幂等剧本
用户用声明的方式通过 参数
Pigsty 诞生之初是为了解决超大规模 PostgreSQL 集群的运维管理问题,背后的想法很简单 —— 我们需要有在十分钟内在就绪的服务器上复刻整套基础设施(100+数据库集群 + PG/Redis + 可观测性)的能力。
任何 GUI + ClickOps 都无法在如此短的时间内完成如此复杂的任务,这让 CLI + IaC 成为唯一的选择 —— 它提供了精确,高效的控制能力。
配置清单 pigsty.yml
您可以使用 git 对这份部署的 “种子/基因” 进行版本控制与审计,而且,Pigsty 甚至支持将配置清单以数据库表的形式存储在 PostgreSQL CMDB 中,更进一步实现 Infra as Data 的能力。
无缝与您现有的工作流程集成与对接。
IaC 面向专业用户与企业场景而设计,但也针对个人开发者,SMB 进行了深度优化。
即使您并非专业 DBA,也无需了解这几百个调节开关与旋钮,所有参数都带有表现良好的默认值,
您完全可以在 零配置 的情况下,获得一个开箱即用的单机数据库节点;
简单地再添加两行 IP 地址,就能获得一套企业级的高可用的 PostgreSQL 集群。
声明模块 以下面的默认配置片段为例,这段配置描述了一个节点 10.10.10.10,其上安装了 INFRANODEETCDPGSQL
# 监控、告警、DNS、NTP 等基础设施集群...
infra : { hosts : { 10.10.10.10 : { infra_seq : 1 } } }
# minio 集群,兼容 s3 的对象存储
minio : { hosts : { 10.10.10.10 : { minio_seq: 1 } }, vars : { minio_cluster : minio } }
# etcd 集群,用作 PostgreSQL 高可用所需的 DCS
etcd : { hosts : { 10.10.10.10 : { etcd_seq: 1 } }, vars : { etcd_cluster : etcd } }
# PGSQL 示例集群: pg-meta
pg-meta : { hosts : { 10.10.10.10 : { pg_seq: 1, pg_role: primary }, vars : { pg_cluster : pg-meta } }
要真正安装这些模块,执行以下剧本:
./infra.yml -l 10.10.10.10 # 在节点 10.10.10.10 上初始化 infra 模块
./etcd.yml -l 10.10.10.10 # 在节点 10.10.10.10 上初始化 etcd 模块
./minio.yml -l 10.10.10.10 # 在节点 10.10.10.10 上初始化 minio 模块
./pgsql.yml -l 10.10.10.10 # 在节点 10.10.10.10 上初始化 pgsql 模块
声明集群 您可以声明 PostgreSQL 数据库集群,在多个节点上安装 PGSQL
例如,要在以下三个已被 Pigsty 纳管的节点上,部署一个使用流复制组建的三节点高可用 PostgreSQL 集群,
您可以在配置文件 pigsty.ymlall.children 中添加以下定义:
pg-test :
hosts :
10.10.10.11 : { pg_seq: 1, pg_role : primary }
10.10.10.12 : { pg_seq: 2, pg_role : replica }
10.10.10.13 : { pg_seq: 3, pg_role : offline }
vars : { pg_cluster : pg-test }
定义完后,可以使用 剧本
bin/pgsql-add pg-test # 创建 pg-test 集群
你可以使用不同的的实例角色,例如 主库 从库 离线从库 延迟从库 同步备库 备份集群 Citus集群 Redis MinIO Etcd
定制集群内容 您不仅可以使用声明式的方式定义集群,还可以定义集群中的数据库、用户、服务、HBA 规则等内容,例如,下面的配置文件对默认的 pg-meta 单节点数据库集群的内容进行了深度定制:
包括:声明了六个业务数据库与七个业务用户,添加了一个额外的 standby 服务(同步备库,提供无复制延迟的读取能力),定义了一些额外的 pg_hba 规则,一个指向集群主库的 L2 VIP 地址,与自定义的备份策略。
pg-meta :
hosts : { 10.10.10.10 : { pg_seq: 1, pg_role: primary , pg_offline_query : true } }
vars :
pg_cluster : pg-meta
pg_databases : # define business databases on this cluster, array of database definition
- name : meta # REQUIRED, `name` is the only mandatory field of a database definition
baseline : cmdb.sql # optional, database sql baseline path, (relative path among ansible search path, e.g files/)
pgbouncer : true # optional, add this database to pgbouncer database list? true by default
schemas : [ pigsty] # optional, additional schemas to be created, array of schema names
extensions: # optional, additional extensions to be installed : array of `{name[,schema]}`
- { name: postgis , schema : public }
- { name : timescaledb }
comment : pigsty meta database # optional, comment string for this database
owner : postgres # optional, database owner, postgres by default
template : template1 # optional, which template to use, template1 by default
encoding : UTF8 # optional, database encoding, UTF8 by default. (MUST same as template database)
locale : C # optional, database locale, C by default. (MUST same as template database)
lc_collate : C # optional, database collate, C by default. (MUST same as template database)
lc_ctype : C # optional, database ctype, C by default. (MUST same as template database)
tablespace : pg_default # optional, default tablespace, 'pg_default' by default.
allowconn : true # optional, allow connection, true by default. false will disable connect at all
revokeconn : false # optional, revoke public connection privilege. false by default. (leave connect with grant option to owner)
register_datasource : true # optional, register this database to grafana datasources? true by default
connlimit : -1 # optional, database connection limit, default -1 disable limit
pool_auth_user : dbuser_meta # optional, all connection to this pgbouncer database will be authenticated by this user
pool_mode : transaction # optional, pgbouncer pool mode at database level, default transaction
pool_size : 64 # optional, pgbouncer pool size at database level, default 64
pool_size_reserve : 32 # optional, pgbouncer pool size reserve at database level, default 32
pool_size_min : 0 # optional, pgbouncer pool size min at database level, default 0
pool_max_db_conn : 100 # optional, max database connections at database level, default 100
- { name: grafana ,owner: dbuser_grafana ,revokeconn: true ,comment : grafana primary database }
- { name: bytebase ,owner: dbuser_bytebase ,revokeconn: true ,comment : bytebase primary database }
- { name: kong ,owner: dbuser_kong ,revokeconn: true ,comment : kong the api gateway database }
- { name: gitea ,owner: dbuser_gitea ,revokeconn: true ,comment : gitea meta database }
- { name: wiki ,owner: dbuser_wiki ,revokeconn: true ,comment : wiki meta database }
pg_users : # define business users/roles on this cluster, array of user definition
- name : dbuser_meta # REQUIRED, `name` is the only mandatory field of a user definition
password : DBUser.Meta # optional, password, can be a scram-sha-256 hash string or plain text
login : true # optional, can log in, true by default (new biz ROLE should be false)
superuser : false # optional, is superuser? false by default
createdb : false # optional, can create database? false by default
createrole : false # optional, can create role? false by default
inherit : true # optional, can this role use inherited privileges? true by default
replication : false # optional, can this role do replication? false by default
bypassrls : false # optional, can this role bypass row level security? false by default
pgbouncer : true # optional, add this user to pgbouncer user-list? false by default (production user should be true explicitly)
connlimit : -1 # optional, user connection limit, default -1 disable limit
expire_in : 3650 # optional, now + n days when this role is expired (OVERWRITE expire_at)
expire_at : '2030-12-31' # optional, YYYY-MM-DD 'timestamp' when this role is expired (OVERWRITTEN by expire_in)
comment : pigsty admin user # optional, comment string for this user/role
roles: [dbrole_admin] # optional, belonged roles. default roles are : dbrole_{admin,readonly,readwrite,offline}
parameters : {} # optional, role level parameters with `ALTER ROLE SET`
pool_mode : transaction # optional, pgbouncer pool mode at user level, transaction by default
pool_connlimit : -1 # optional, max database connections at user level, default -1 disable limit
- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly], comment : read-only viewer for meta database}
- {name: dbuser_grafana ,password: DBUser.Grafana ,pgbouncer: true ,roles: [dbrole_admin] ,comment : admin user for grafana database }
- {name: dbuser_bytebase ,password: DBUser.Bytebase ,pgbouncer: true ,roles: [dbrole_admin] ,comment : admin user for bytebase database }
- {name: dbuser_kong ,password: DBUser.Kong ,pgbouncer: true ,roles: [dbrole_admin] ,comment : admin user for kong api gateway }
- {name: dbuser_gitea ,password: DBUser.Gitea ,pgbouncer: true ,roles: [dbrole_admin] ,comment : admin user for gitea service }
- {name: dbuser_wiki ,password: DBUser.Wiki ,pgbouncer: true ,roles: [dbrole_admin] ,comment : admin user for wiki.js service }
pg_services : # extra services in addition to pg_default_services, array of service definition
# standby service will route {ip|name}:5435 to sync replica's pgbouncer (5435->6432 standby)
- name: standby # required, service name, the actual svc name will be prefixed with `pg_cluster`, e.g : pg-meta-standby
port : 5435 # required, service exposed port (work as kubernetes service node port mode)
ip : "*" # optional, service bind ip address, `*` for all ip by default
selector : "[]" # required, service member selector, use JMESPath to filter inventory
dest : default # optional, destination port, default|postgres|pgbouncer|<port_number>, 'default' by default
check : /sync # optional, health check url path, / by default
backup : "[? pg_role == `primary`]" # backup server selector
maxconn : 3000 # optional, max allowed front-end connection
balance: roundrobin # optional, haproxy load balance algorithm (roundrobin by default, other : leastconn)
options : 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
pg_hba_rules :
- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title : 'allow grafana dashboard access cmdb from infra nodes' }
pg_vip_enabled : true
pg_vip_address : 10.10.10.2 /24
pg_vip_interface : eth1
node_crontab : # make a full backup 1 am everyday
- '00 01 * * * postgres /pg/bin/pg-backup full'
声明访问控制 您还可以通过声明式的配置,深度定制 Pigsty 的访问控制能力。例如下面的配置文件对 pg-meta 集群进行了深度安全定制:
使用三节点核心集群模板:crit.yml,确保数据一致性有限,故障切换数据零丢失。
启用了 L2 VIP,并将数据库与连接池的监听地址限制在了 本地环回IP + 内网IP + VIP 三个特定地址。
模板强制启用了 Patroni 的 SSL API,与 Pgbouncer 的 SSL,并在 HBA 规则中强制要求使用 SSL 访问数据库集群。
同时还在 pg_libs 中启用了 $libdir/passwordcheck 扩展,来强制执行密码强度安全策略。
最后,还单独声明了一个 pg-meta-delay 集群,作为 pg-meta 在一个小时前的延迟镜像从库,用于紧急数据误删恢复。
pg-meta : # 3 instance postgres cluster `pg-meta`
hosts :
10.10.10.10 : { pg_seq: 1, pg_role : primary }
10.10.10.11 : { pg_seq: 2, pg_role : replica }
10.10.10.12 : { pg_seq: 3, pg_role: replica , pg_offline_query : true }
vars :
pg_cluster : pg-meta
pg_conf : crit.yml
pg_users :
- { name: dbuser_meta , password: DBUser.Meta , pgbouncer: true , roles: [ dbrole_admin ] , comment : pigsty admin user }
- { name: dbuser_view , password: DBUser.Viewer , pgbouncer: true , roles: [ dbrole_readonly ] , comment : read-only viewer for meta database }
pg_databases :
- {name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions : [ {name: postgis, schema : public}, {name: timescaledb}]}
pg_default_service_dest : postgres
pg_services :
- { name: standby ,src_ip : "*" ,port: 5435 , dest: default ,selector : "[]" , backup : "[? pg_role == `primary`]" }
pg_vip_enabled : true
pg_vip_address : 10.10.10.2 /24
pg_vip_interface : eth1
pg_listen : '${ip},${vip},${lo}'
patroni_ssl_enabled : true
pgbouncer_sslmode : require
pgbackrest_method : minio
pg_libs : 'timescaledb, $libdir/passwordcheck, pg_stat_statements, auto_explain' # add passwordcheck extension to enforce strong password
pg_default_roles : # default roles and users in postgres cluster
- { name: dbrole_readonly ,login: false ,comment : role for global read-only access }
- { name: dbrole_offline ,login: false ,comment : role for restricted read-only access }
- { name: dbrole_readwrite ,login: false ,roles: [dbrole_readonly] ,comment : role for global read-write access }
- { name: dbrole_admin ,login: false ,roles: [pg_monitor, dbrole_readwrite] ,comment : role for object creation }
- { name: postgres ,superuser: true ,expire_in: 7300 ,comment : system superuser }
- { name: replicator ,replication: true ,expire_in: 7300 ,roles: [pg_monitor, dbrole_readonly] ,comment : system replicator }
- { name: dbuser_dba ,superuser: true ,expire_in: 7300 ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 , comment : pgsql admin user }
- { name: dbuser_monitor ,roles: [pg_monitor] ,expire_in: 7300 ,pgbouncer: true ,parameters : {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment : pgsql monitor user }
pg_default_hba_rules : # postgres host-based auth rules by default
- {user : '${dbsu}' ,db: all ,addr: local ,auth: ident ,title : 'dbsu access via local os user ident' }
- {user : '${dbsu}' ,db: replication ,addr: local ,auth: ident ,title : 'dbsu replication from local os ident' }
- {user : '${repl}' ,db: replication ,addr: localhost ,auth: ssl ,title : 'replicator replication from localhost' }
- {user : '${repl}' ,db: replication ,addr: intra ,auth: ssl ,title : 'replicator replication from intranet' }
- {user : '${repl}' ,db: postgres ,addr: intra ,auth: ssl ,title : 'replicator postgres db from intranet' }
- {user : '${monitor}' ,db: all ,addr: localhost ,auth: pwd ,title : 'monitor from localhost with password' }
- {user : '${monitor}' ,db: all ,addr: infra ,auth: ssl ,title : 'monitor from infra host with password' }
- {user : '${admin}' ,db: all ,addr: infra ,auth: ssl ,title : 'admin @ infra nodes with pwd & ssl' }
- {user : '${admin}' ,db: all ,addr: world ,auth: cert ,title : 'admin @ everywhere with ssl & cert' }
- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: ssl ,title : 'pgbouncer read/write via local socket' }
- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: ssl ,title : 'read/write biz user via password' }
- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: ssl ,title : 'allow etl offline tasks from intranet' }
pgb_default_hba_rules : # pgbouncer host-based authentication rules
- {user : '${dbsu}' ,db: pgbouncer ,addr: local ,auth: peer ,title : 'dbsu local admin access with os ident' }
- {user: 'all' ,db: all ,addr: localhost ,auth: pwd ,title : 'allow all user local access with pwd' }
- {user : '${monitor}' ,db: pgbouncer ,addr: intra ,auth: ssl ,title : 'monitor access via intranet with pwd' }
- {user : '${monitor}' ,db: all ,addr: world ,auth: deny ,title : 'reject all other monitor access addr' }
- {user : '${admin}' ,db: all ,addr: intra ,auth: ssl ,title : 'admin access via intranet with pwd' }
- {user : '${admin}' ,db: all ,addr: world ,auth: deny ,title : 'reject all other admin access addr' }
- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title : 'allow all user intra access with pwd' }
# OPTIONAL delayed cluster for pg-meta
pg-meta-delay : # delayed instance for pg-meta (1 hour ago)
hosts : { 10.10.10.13 : { pg_seq: 1, pg_role: primary, pg_upstream: 10.10.10.10, pg_delay : 1h } }
vars : { pg_cluster : pg-meta-delay }
Citus分布式集群 下面是一个四节点的 Citus 分布式集群的声明式配置:
all :
children :
pg-citus0 : # citus coordinator, pg_group = 0
hosts : { 10.10.10.10 : { pg_seq: 1, pg_role : primary } }
vars : { pg_cluster: pg-citus0 , pg_group : 0 }
pg-citus1 : # citus data node 1
hosts : { 10.10.10.11 : { pg_seq: 1, pg_role : primary } }
vars : { pg_cluster: pg-citus1 , pg_group : 1 }
pg-citus2 : # citus data node 2
hosts : { 10.10.10.12 : { pg_seq: 1, pg_role : primary } }
vars : { pg_cluster: pg-citus2 , pg_group : 2 }
pg-citus3 : # citus data node 3, with an extra replica
hosts :
10.10.10.13 : { pg_seq: 1, pg_role : primary }
10.10.10.14 : { pg_seq: 2, pg_role : replica }
vars : { pg_cluster: pg-citus3 , pg_group : 3 }
vars : # global parameters for all citus clusters
pg_mode: citus # pgsql cluster mode : citus
pg_shard: pg-citus # citus shard name : pg-citus
patroni_citus_db : meta # citus distributed database name
pg_dbsu_password : DBUser.Postgres # all dbsu password access for citus cluster
pg_users : [ { name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles : [ dbrole_admin ] } ]
pg_databases : [ { name: meta ,extensions : [ { name : citus }, { name: postgis }, { name: timescaledb } ] } ]
pg_hba_rules :
- { user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title : 'all user ssl access from localhost' }
- { user: 'all' ,db: all ,addr: intra ,auth: ssl ,title : 'all user ssl access from intranet' }
Redis集群 下面给出了 Redis 主从集群、哨兵集群、以及 Redis Cluster 的声明配置样例
redis-ms : # redis classic primary & replica
hosts : { 10.10.10.10 : { redis_node: 1 , redis_instances : { 6379 : { }, 6380 : { replica_of : '10.10.10.10 6379' } } } }
vars : { redis_cluster: redis-ms ,redis_password: 'redis.ms' ,redis_max_memory : 64MB }
redis-meta : # redis sentinel x 3
hosts : { 10.10.10.11 : { redis_node: 1 , redis_instances : { 26379 : { } ,26380 : { } ,26381 : { } } } }
vars :
redis_cluster : redis-meta
redis_password : 'redis.meta'
redis_mode : sentinel
redis_max_memory : 16MB
redis_sentinel_monitor : # primary list for redis sentinel, use cls as name, primary ip:port
- { name: redis-ms, host: 10.10.10.10, port: 6379 ,password: redis.ms, quorum : 2 }
redis-test: # redis native cluster : 3m x 3s
hosts :
10.10.10.12 : { redis_node: 1 ,redis_instances : { 6379 : { } ,6380 : { } ,6381 : { } } }
10.10.10.13 : { redis_node: 2 ,redis_instances : { 6379 : { } ,6380 : { } ,6381 : { } } }
vars : { redis_cluster: redis-test ,redis_password: 'redis.test' ,redis_mode: cluster, redis_max_memory : 32MB }
ETCD集群 下面给出了一个三节点的 Etcd 集群声明式配置样例:
etcd : # dcs service for postgres/patroni ha consensus
hosts : # 1 node for testing, 3 or 5 for production
10.10.10.10 : { etcd_seq : 1 } # etcd_seq required
10.10.10.11 : { etcd_seq : 2 } # assign from 1 ~ n
10.10.10.12 : { etcd_seq : 3 } # odd number please
vars : # cluster level parameter override roles/etcd
etcd_cluster : etcd # mark etcd cluster name etcd
etcd_safeguard : false # safeguard against purging
etcd_clean : true # purge etcd during init process
MinIO集群 下面给出了一个三节点的 MinIO 集群声明式配置样例:
minio :
hosts :
10.10.10.10 : { minio_seq : 1 }
10.10.10.11 : { minio_seq : 2 }
10.10.10.12 : { minio_seq : 3 }
vars :
minio_cluster : minio
minio_data : '/data{1...2}' # 每个节点使用两块磁盘
minio_node : '${minio_cluster}-${minio_seq}.pigsty' # 节点名称的模式
haproxy_services :
- name : minio # [必选] 服务名称,需要唯一
port : 9002 # [必选] 服务端口,需要唯一
options :
- option httpchk
- option http-keep-alive
- http-check send meth OPTIONS uri /minio/health/live
- http-check expect status 200
servers :
- { name: minio-1 ,ip: 10.10.10.10 , port: 9000 , options : 'check-ssl ca-file /etc/pki/ca.crt check port 9000' }
- { name: minio-2 ,ip: 10.10.10.11 , port: 9000 , options : 'check-ssl ca-file /etc/pki/ca.crt check port 9000' }
- { name: minio-3 ,ip: 10.10.10.12 , port: 9000 , options : 'check-ssl ca-file /etc/pki/ca.crt check port 9000' }
3.1 - 配置清单 使用声明式的配置文件描述你需要的基础设施与集群
每一套 Pigsty 部署都对应着一份 配置清单 (Inventory),描述了基础设施与数据库集群的关键属性。
配置文件 Pigsty 默认使用 Ansible YAML 配置格式 pigsty.yml
~/pigsty
^---- pigsty.yml # <---- 默认配置文件
您可以直接修改该配置文件来定制您的部署,或者使用 Pigsty 提供的 配置向导 configure
配置结构 配置清单使用标准的 Ansible YAML 配置格式 全局参数 (all.vars)和多个 组 (all.children)。
您可以在 all.children 中定义新集群,并使用全局变量描述基础设施:all.vars,它看起来像这样:
all : # 顶级对象:all
vars : {...} # 全局参数
children : # 组定义
infra : # 组定义:'infra'
hosts : {...} # 组成员:'infra'
vars : {...} # 组参数:'infra'
etcd : {...} # 组定义:'etcd'
pg-meta : {...} # 组定义:'pg-meta'
pg-test : {...} # 组定义:'pg-test'
redis-test : {...} # 组定义:'redis-test'
# ...
集群定义 每个 Ansible 组可能代表一个集群,可以是节点集群、PostgreSQL 集群、Redis 集群、Etcd 集群或 MinIO 集群等…
集群定义由两部分组成:集群成员 (hosts集群参数 (vars<cls>.hosts 中定义集群成员,并在 <cls>.vars 中使用 配置参数
all :
children : # ansible 组列表
pg-test : # ansible 组名
hosts : # ansible 组内实例(集群成员)
10.10.10.11 : { pg_seq: 1, pg_role : primary } # 主机 1
10.10.10.12 : { pg_seq: 2, pg_role : replica } # 主机 2
10.10.10.13 : { pg_seq: 3, pg_role : offline } # 主机 3
vars : # ansible 组变量(集群参数)
pg_cluster : pg-test
集群级别的 vars (集群参数)将覆盖全局参数,实例级别的 vars 将覆盖集群参数和全局参数。
拆分配置 如果您的部署规模较大,或者希望更好地组织配置文件,
可以将配置清单 拆分为多个文件
inventory/
├── hosts.yml # 主机和集群定义
├── group_vars/
│ ├── all.yml # 全局默认变量 (对应 all.vars)
│ ├── infra.yml # infra 组变量
│ ├── etcd.yml # etcd 组变量
│ └── pg-meta.yml # pg-meta 集群变量
└── host_vars/
├── 10.10.10.10.yml # 特定主机变量
└── 10.10.10.11.yml
您可以将集群成员定义放在 hosts.yml 文件中,将集群层面的 配置参数 group_vars 目录下的对应文件中。
切换配置 您可以在执行剧本的时候,通过 -i 参数,临时指定另外的配置清单文件。
./pgsql.yml -i another_config.yml
./infra.yml -i nginx_config.yml
此外,Ansible 支持多种配置方式,您可以使用本地 yaml|ini 配置文件,或者是 CMDB 与任意的动态配置脚本作为配置源。
在 Pigsty 中,我们通过 Pigsty 主目录中的 ansible.cfgpigsty.yml配置清单 ,您可按需修改。
[defaults]
inventory = pigsty.yml
此外,Pigsty 还支持使用 CMDB 元数据库
3.2 - 配置向导 使用 configure 脚本根据当前环境自动生成推荐的配置文件。
Pigsty 提供了一个 configure配置向导 ,它能根据当前环境,自动生成合适的 pigsty.yml 配置文件。
这是一个 可选 的脚本:如果您已经了解了如何配置 Pigsty,大可以直接编辑 pigsty.yml 配置文件,跳过向导。
快速开始 进入 pigsty 源码家目录中,执行 ./configure 即可自动运行配置向导。不带任何参数时,默认使用 meta
cd ~/pigsty
./configure # 交互式配置向导,自动检测环境并生成配置
该命令会以选定的模板为基础,检测当前节点的 IP 地址与区域,并生成适合当前环境的 pigsty.yml 配置文件。
功能说明 configurepigsty.yml 配置文件。
检测当前节点 IP 地址,如果有多个 IP,则要求用户输入一个 首要的 IP 地址 作为当前节点的身份标识 使用 IP 地址替换配置模板中的占位符 10.10.10.10admin_ip 检测当前区域,将 regiondefaultchina 针对小微实例(vCPU < 4),为 node_tunepg_conftiny 如果指定了 -vpg_version 如果指定了 -g强烈推荐 ) 当 PG 大版本 ≥ 17 时优先使用内置的 C.UTF-8C.UTF-8 检测当前环境中,用于执行部署的核心依赖 ansible 同时检测部署目标节点是否 ssh 可达,并可以使用 sudo 执行命令。(-s 使用示例 # 基本用法
./configure # 交互式配置向导
./configure -i 10.10.10.10 # 指定主 IP 地址
# 指定配置模板
./configure -c meta # 使用默认单节点模板(默认)
./configure -c rich # 使用功能丰富的单节点模板
./configure -c slim # 使用精简模板(仅 PGSQL + ETCD)
./configure -c ha/full # 使用 4 节点高可用沙箱模板
./configure -c ha/trio # 使用 3 节点高可用模板
./configure -c app/supa # 使用 Supabase 自托管模板
# 指定 PostgreSQL 版本
./configure -v 17 # 使用 PostgreSQL 17
./configure -v 16 # 使用 PostgreSQL 16
./configure -c rich -v 16 # rich 模板 + PG 16
# 区域与代理
./configure -r china # 使用中国镜像源
./configure -r europe # 使用欧洲镜像源
./configure -x # 导入当前代理环境变量
# 跳过与自动化
./configure -s # 跳过 IP 探测,保留占位符
./configure -n -i 10.10.10.10 # 非交互模式,指定 IP
./configure -c ha/full -s # 4 节点模板,跳过 IP 替换
# 安全增强
./configure -g # 生成随机密码
./configure -c meta -g -i 10.10.10.10 # 完整生产配置
# 指定输出与 SSH 端口
./configure -o prod.yml # 输出到 prod.yml
./configure -p 2222 # 使用 SSH 端口 2222
命令参数 ./configure
[ -c| --conf <template>] # 配置模板名称(meta|rich|slim|ha/full|...)
[ -i| --ip <ipaddr>] # 指定主 IP 地址
[ -v| --version <pgver>] # PostgreSQL 大版本号(13|14|15|16|17|18)
[ -r| --region <region>] # 上游软件仓库区域(default|china|europe)
[ -o| --output <file>] # 输出配置文件路径(默认:pigsty.yml)
[ -s| --skip] # 跳过 IP 地址探测与替换
[ -x| --proxy] # 从环境变量导入代理设置
[ -n| --non-interactive] # 非交互模式(不询问任何问题)
[ -p| --port <port>] # 指定 SSH 端口
[ -g| --generate] # 生成随机密码
[ -h| --help] # 显示帮助信息
参数详解 参数 说明 -c, --conf从 conf/<template>.yml 生成配置文件,支持子目录如 ha/full -i, --ip用指定 IP 替换配置模板中的占位符 10.10.10.10 -v, --version指定 PostgreSQL 大版本号(13-18),不指定时保持模板默认值 -r, --region设置软件仓库镜像区域:default(默认)、china(中国镜像)、europe(欧洲镜像) -o, --output指定输出文件路径,默认为 pigsty.yml -s, --skip跳过 IP 地址探测与替换,保留模板中的 10.10.10.10 占位符 -x, --proxy将当前环境的代理变量(HTTP_PROXY、HTTPS_PROXY、ALL_PROXY、NO_PROXY)写入配置 -n, --non-interactive非交互模式,不询问任何问题(需配合 -i 指定 IP) -p, --port指定 SSH 端口(非默认 22 端口时使用) -g, --generate为配置文件中的密码生成随机值,提高安全性(强烈推荐)
执行流程 configure 脚本按照以下顺序执行检测与配置:
┌─────────────────────────────────────────────────────────────┐
│ configure 执行流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 1. check_region 检测网络区域(GFW 检测) │
│ ↓ │
│ 2. check_version 验证 PostgreSQL 版本号 │
│ ↓ │
│ 3. check_kernel 检测操作系统内核(Linux/Darwin) │
│ ↓ │
│ 4. check_machine 检测 CPU 架构(x86_64/aarch64) │
│ ↓ │
│ 5. check_package_manager 检测包管理器(dnf/yum/apt) │
│ ↓ │
│ 6. check_vendor_version 检测 OS 发行版与版本 │
│ ↓ │
│ 7. check_sudo 检测免密 sudo 权限 │
│ ↓ │
│ 8. check_ssh 检测免密 SSH 到本机 │
│ ↓ │
│ 9. check_proxy 处理代理环境变量 │
│ ↓ │
│ 10. check_ipaddr 探测/输入主 IP 地址 │
│ ↓ │
│ 11. check_admin 验证管理员 SSH + Sudo 权限 │
│ ↓ │
│ 12. check_conf 选择配置模板 │
│ ↓ │
│ 13. check_config 生成配置文件 │
│ ↓ │
│ 14. check_utils 检测 Ansible 等工具是否安装 │
│ ↓ │
│ ✓ 配置完成,输出 pigsty.yml │
│ │
└─────────────────────────────────────────────────────────────┘
自动化行为 区域检测 脚本会自动检测网络环境,判断是否在中国大陆(GFW 内):
# 通过访问 Google 判断网络环境
curl -I -s --connect-timeout 1 www.google.com
如果无法访问 Google,自动设置 region: china 使用国内镜像 如果可以访问,使用 region: default 默认镜像 可通过 -r 参数手动指定区域 IP 地址处理 脚本按以下优先级确定主 IP 地址:
命令行参数 :如果通过 -i 指定了 IP,直接使用单 IP 探测 :如果当前节点只有一个 IP,自动使用演示 IP 检测 :如果检测到 10.10.10.10,自动选择(用于沙箱环境)交互式输入 :多个 IP 时,提示用户选择或输入[ WARN] Multiple IP address candidates found:
( 1) 192.168.1.100 inet 192.168.1.100/24 scope global eth0
( 2) 10.10.10.10 inet 10.10.10.10/24 scope global eth1
[ IN ] INPUT primary_ip address ( of current meta node, e.g 10.10.10.10) :
= > 10.10.10.10
低端硬件优化 当检测到 CPU 核心数 ≤ 4 时,脚本会自动调整配置:
[ WARN] replace oltp template with tiny due to cpu < 4
这样可以确保在低配虚拟机上也能顺利运行。
Locale 设置 脚本会在以下情况自动启用 C.UTF-8 作为默认 Locale:
PostgreSQL 版本 ≥ 17(内置 Locale Provider 支持) 或者 当前系统支持 C.UTF-8 / C.utf8 Localepg_locale : C.UTF-8
pg_lc_collate : C.UTF-8
pg_lc_ctype : C.UTF-8
中国区特殊处理 当区域设置为 china 时,脚本会自动:
启用 docker_registry_mirrors Docker 镜像加速 启用 PIP_MIRROR_URL Python 镜像加速 密码生成 使用 -g 参数时,脚本会为以下密码生成 24 位随机字符串:
密码参数 说明 grafana_admin_passwordGrafana 管理员密码 pg_admin_passwordPostgreSQL 管理员密码 pg_monitor_passwordPostgreSQL 监控用户密码 pg_replication_passwordPostgreSQL 复制用户密码 patroni_passwordPatroni API 密码 haproxy_admin_passwordHAProxy 管理密码 minio_secret_keyMinIO Secret Key etcd_root_passwordETCD Root 密码
同时还会替换以下占位符密码:
DBUser.Meta → 随机密码DBUser.Viewer → 随机密码S3User.Backup → 随机密码S3User.Meta → 随机密码S3User.Data → 随机密码$ ./configure -g
[ INFO] generating random passwords...
grafana_admin_password : xK9mL2nP4qR7sT1vW3yZ5bD8
pg_admin_password : aB3cD5eF7gH9iJ1kL2mN4oP6
...
[ INFO] random passwords generated, check and save them
配置模板 脚本从 conf/ 目录读取配置模板,支持以下模板:
核心模板 模板 说明 meta默认模板 :单节点安装,包含 INFRA + NODE + ETCD + PGSQLrich功能丰富版:包含几乎所有扩展、MinIO、本地仓库 slim精简版:仅 PostgreSQL + ETCD,无监控基础设施 fat完整版:rich 基础上安装更多扩展 pgsql纯 PostgreSQL 模板 infra纯基础设施模板
高可用模板 (ha/) 模板 说明 ha/dual2 节点高可用集群 ha/trio3 节点高可用集群 ha/full4 节点完整沙箱环境 ha/safe安全加固版高可用配置 ha/simu42 节点大规模仿真环境
应用模板 (app/) 模板 说明 supabaseSupabase 自托管配置 app/difyDify AI 平台配置 app/odooOdoo ERP 配置 app/teableTeable 表格数据库配置 app/registryDocker Registry 配置
特殊内核模板 模板 说明 ivoryIvorySQL:Oracle 兼容 PostgreSQL mssqlBabelfish:SQL Server 兼容 PostgreSQL polarPolarDB:阿里云开源分布式 PostgreSQL citusCitus:分布式 PostgreSQL orioleOrioleDB:新一代存储引擎
演示模板 (demo/) 模板 说明 demo/demo演示环境配置 demo/redisRedis 集群演示 demo/minioMinIO 集群演示
输出示例 $ ./configure
configure pigsty v4.0.0 begin
[ OK ] region = china
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = rpm,dnf
[ OK ] vendor = rocky ( Rocky Linux)
[ OK ] version = 9 ( 9.5)
[ OK ] sudo = vagrant ok
[ OK ] ssh = [email protected] ok
[ WARN] Multiple IP address candidates found:
( 1) 192.168.121.193 inet 192.168.121.193/24 brd 192.168.121.255 scope global dynamic noprefixroute eth0
( 2) 10.10.10.10 inet 10.10.10.10/24 brd 10.10.10.255 scope global noprefixroute eth1
[ OK ] primary_ip = 10.10.10.10 ( from demo)
[ OK ] admin = [email protected] ok
[ OK ] mode = meta ( el9)
[ OK ] locale = C.UTF-8
[ OK ] ansible = ready
[ OK ] pigsty configured
[ WARN] don' t forget to check it and change passwords!
proceed with ./deploy.yml
环境变量 脚本支持以下环境变量:
环境变量 说明 默认值 PIGSTY_HOMEPigsty 安装目录 ~/pigstyMETADB_URL元数据库连接 URL service=metaHTTP_PROXYHTTP 代理 - HTTPS_PROXYHTTPS 代理 - ALL_PROXY通用代理 - NO_PROXY代理白名单 内置默认值
注意事项 免密访问 :运行 configure 前,确保当前用户具有免密 sudo 权限和免密 SSH 到本机的能力。可以通过 bootstrap 脚本自动配置。
IP 地址选择 :请选择内网 IP 作为主 IP 地址,不要使用公网 IP 或 127.0.0.1。
密码安全 :生产环境务必 修改配置文件中的默认密码,或使用 -g 参数生成随机密码。
配置检查 :脚本执行完成后,建议检查生成的 pigsty.yml 文件,确认配置符合预期。
多次执行 :可以多次运行 configure 重新生成配置,每次会覆盖现有的 pigsty.yml。
macOS 限制 :在 macOS 上运行时,脚本会跳过部分 Linux 特有的检测,并使用占位符 IP 10.10.10.10。macOS 只能作为管理节点使用。
常见问题 如何使用自定义配置模板? 将您的配置文件放到 conf/ 目录下,然后使用 -c 参数指定:
cp my-config.yml ~/pigsty/conf/myconf.yml
./configure -c myconf
如何为多集群生成不同配置? 使用 -o 参数指定不同的输出文件:
./configure -c ha/full -o cluster-a.yml
./configure -c ha/trio -o cluster-b.yml
然后在执行剧本时指定配置文件:
./deploy.yml -i cluster-a.yml
非交互模式下如何处理多 IP? 必须使用 -i 参数明确指定 IP 地址:
./configure -n -i 10.10.10.10
如何保留模板中的占位符 IP? 使用 -s 参数跳过 IP 替换:
./configure -c ha/full -s # 保留 10.10.10.10 占位符
相关文档 配置清单 配置参数 配置模板 安装部署 元数据库 3.3 - 配置参数 使用配置参数对 Pigsty 进行精细化定制
在 配置清单 中,您可以使用各种参数对 Pigsty 进行精细化定制。这些参数涵盖了从基础设施设置到数据库配置的各个方面。
参数列表 Pigsty 提供了约 380+ 个配置参数,分布在 8 个默认模块中,用于精细控制系统的各个方面,完整列表见 参考-参数列表
模块 参数组 参数数 说明 PGSQL 9 123 PostgreSQL 数据库集群的核心配置 INFRA 10 82 基础设施组件:软件源、Nginx、DNS、监控、Grafana 等 NODE 11 83 主机节点调优:身份、DNS、包、调优、安全、管理员、时间、VIP等 ETCD 2 13 分布式配置存储与服务发现 REDIS 1 21 Redis 缓存与数据结构服务器 MINIO 2 21 S3 兼容对象存储服务 FERRET 1 9 MongoDB 兼容数据库 FerretDB DOCKER 1 8 Docker 容器引擎
参数形式 参数 是用于描述实体的 键值对 。键 (Key)是字符串,值 (Value)可以是五种类型之一:布尔值、字符串、数字、数组或对象。
all : # <------- 顶级对象:all
vars :
admin_ip : 10.10.10.10 # <------- 全局配置参数
children :
pg-meta : # <------- pg-meta 分组
vars :
pg_cluster : pg-meta # <------- 集群级别参数
hosts :
10.10.10.10 : # <------- 主机节点 IP
pg_seq : 1
pg_role : primary # <------- 实例级别参数
参数优先级 参数可以在不同级别设置,具有以下优先级:
级别 位置 描述 优先级 命令行 -e 命令行参数通过命令行传入 最高 (5) 主机/实例 <group>.hosts.<host>特定于单个主机的参数 较高 (4) 分组/集群 <group>.vars组/集群中主机共享的参数 中等 (3) 全局 all.vars所有主机共享的参数 较低 (2) 默认 <roles>/default/main.yml角色实现默认值 最低 (1)
以下是关于参数优先级的一些示例:
执行剧本时,使用命令行参数 -e grafana_clean=true 使用主机变量上的实例级别参数 pg_role 覆盖 pg 实例角色 使用组变量上的集群级别参数 pg_cluster 覆盖 pg 集群名称。 使用全局变量上的全局参数 node_ntp_servers 指定全局 NTP 服务器 如果没有设置 pg_versionpgsql18) 除了身份参数 外,每个参数都有适当的默认值,因此无需显式设置。
身份参数 身份参数是特殊的参数,它们会作为实体的 ID 标识符,因此 没有默认值 ,必须 显式设置 。
模块 身份参数 PGSQLpg_cluster, pg_seq, pg_role, …NODEnodename, node_clusterETCDetcd_cluster, etcd_seqMINIOminio_cluster, minio_seqREDISredis_cluster, redis_node, redis_instancesINFRAinfra_seq
例外是,etcd_clusterminio_clusteretcd 与 minio。
但您依然可以使用其他名称部署多套 etcd 或 MinIO 集群。
3.4 - 配置模板 使用预制的配置模板,快速生成适配当前环境的配置文件
在 Pigsty 中,部署的蓝图细节由 配置清单 pigsty.yml
然而,直接编写配置文件可能会让新用户望而生畏。为此,我们提供了一些开箱即用的配置模板,涵盖了常见的使用场景。
每一个模板都是一个预定义的 pigsty.yml 配置文件,包含了适用于特定场景的合理默认值。
您可以根据自己的需要,选择一个模板作为定制起点,然后根据需要进行修改,以满足您的具体需求。
使用模板 Pigsty 提供了 configure配置清单
使用 ./configure -c <conf> 指定配置模板,其中 <conf> 是相对于 conf 目录的路径(可省略 .yml 后缀)。
./configure # 默认使用 meta.yml 配置模板
./configure -c meta # 显式指定使用 meta.yml 单节点模板
./configure -c rich # 使用包含全部扩展与 MinIO 的富功能模板
./configure -c slim # 使用最小化的单节点模板
# 使用不同的数据库内核
./configure -c pgsql # 原生 PostgreSQL 内核,基础功能 (13~18)
./configure -c citus # Citus 分布式高可用 PostgreSQL (14~17)
./configure -c mssql # Babelfish 内核,兼容 SQL Server 协议 (15)
./configure -c polar # PolarDB PG 内核,Aurora/RAC 风格 (15)
./configure -c ivory # IvorySQL 内核,兼容 Oracle 语法 (18)
./configure -c mysql # OpenHalo 内核,兼容 MySQL (14)
./configure -c pgtde # Percona PostgreSQL Server 透明加密 (18)
./configure -c oriole # OrioleDB 内核,OLTP 增强 (17)
./configure -c supabase # Supabase 自托管配置 (15~18)
# 使用多节点高可用模板
./configure -c ha/dual # 使用 2 节点高可用模板
./configure -c ha/trio # 使用 3 节点高可用模板
./configure -c ha/full # 使用 4 节点高可用模板
如果不指定模板,Pigsty 默认使用 meta.yml 单节点配置模板。
模板列表 主要模板 以下是单节点配置模板,可用于在单台服务器上安装 Pigsty:
数据库内核模板 适用于各类数据库管理系统与内核的模板:
您可以后续添加更多节点,或使用 高可用模板 在一开始就规划好集群。
高可用模板 您可以配置 Pigsty 在多节点上运行,组成高可用(HA)集群:
应用模板 您可以使用以下模板运行 Docker 应用/软件:
演示模板 除主要模板外,Pigsty 还提供了一组面向不同场景的演示模板:
构建模板 以下配置模板用于开发和测试目的:
模板 说明 build.ymlEL 9/10、Debian 12/13、Ubuntu 22.04/24.04 开源构建配置
3.5 - 元数据库 使用 PostgreSQL 作为 CMDB 元数据库,存储 Ansible 配置清单。
Pigsty 允许您使用 PostgreSQL 元数据库 作为动态配置源,取代静态的 YAML 配置文件,实现更强大的配置管理能力。
概览 CMDB (Configuration Management Database,配置管理数据库)是一种将配置信息存储在数据库中进行管理的方式。
在 Pigsty 中,默认的配置源是一个静态 YAML 文件 pigsty.yml,
它作为 Ansible 的 配置清单
这种方式简单直接,但当基础设施规模扩大、需要复杂精细的管理与外部集成时,单一的静态文件难以满足需求。
特性 静态 YAML 文件 CMDB 元数据库 查询能力 手工搜索/grep SQL 任意条件查询,聚合分析 版本控制 依赖 Git 或手工备份 数据库事务,审计日志,时间旅行快照 权限控制 文件系统权限,粗粒度 PostgreSQL 数据库精细访问控制 并发编辑 需要锁文件或合并冲突 数据库事务天然支持并发 外部集成 需要解析 YAML 标准 SQL 接口,任意语言轻松对接 规模扩展 文件过大时难以维护 管理规模伸缩至物理极限 动态生成 静态文件,修改后需手动应用 即时生效,实时反映配置变更
Pigsty 在样板数据库 pg-meta.meta
工作原理 CMDB 的核心思想是用一个 动态脚本 替换静态配置文件。
Ansible 支持使用可执行脚本作为配置清单,只要脚本输出符合 JSON 格式的清单数据即可。
当您启用 CMDB 后,Pigsty 会创建一个名为 inventory.sh 的动态清单脚本:
#!/bin/bash
${ METADB_URL } -AXtwc 'SELECT text FROM pigsty.inventory;'
这个脚本的作用很简单:每次 Ansible 需要读取配置清单时,它会从 PostgreSQL 数据库的 pigsty.inventory 视图中查询配置数据,并以 JSON 格式返回。
整体架构如下:
flowchart LR
conf["bin/inventory_conf"]
tocmdb["bin/inventory_cmdb"]
load["bin/inventory_load"]
ansible["🚀 Ansible"]
subgraph static["📄 静态配置模式"]
yml[("pigsty.yml")]
end
subgraph dynamic["🗄️ CMDB 动态模式"]
sh["inventory.sh"]
cmdb[("PostgreSQL CMDB")]
end
conf -->|"切换"| yml
yml -->|"加载配置"| load
load -->|"写入"| cmdb
tocmdb -->|"切换"| sh
sh --> cmdb
yml --> ansible
cmdb --> ansible 数据模型 CMDB 的数据库模式定义在 files/cmdb.sqlpigsty 模式下。
核心数据表 表名 说明 主键 pigsty.group集群/分组定义,对应 Ansible 的 group clspigsty.host主机定义,属于某个分组 (cls, ip)pigsty.global_var全局变量,对应 all.vars keypigsty.group_var分组变量,对应 all.children.<cls>.vars (cls, key)pigsty.host_var主机变量,对应主机级别的变量 (cls, ip, key)pigsty.default_var默认变量定义,存储参数的元信息 keypigsty.job作业记录表,记录执行的任务 id
表结构详解 集群表 pigsty.group
CREATE TABLE pigsty . group (
cls TEXT PRIMARY KEY , -- 集群名称,主键
ctime TIMESTAMPTZ DEFAULT now (), -- 创建时间
mtime TIMESTAMPTZ DEFAULT now () -- 修改时间
);
主机表 pigsty.host
CREATE TABLE pigsty . host (
cls TEXT NOT NULL REFERENCES pigsty . group ( cls ), -- 所属集群
ip INET NOT NULL , -- 主机 IP 地址
ctime TIMESTAMPTZ DEFAULT now (),
mtime TIMESTAMPTZ DEFAULT now (),
PRIMARY KEY ( cls , ip )
);
全局变量表 pigsty.global_var
CREATE TABLE pigsty . global_var (
key TEXT PRIMARY KEY , -- 变量名
value JSONB NULL , -- 变量值(JSON 格式)
mtime TIMESTAMPTZ DEFAULT now () -- 修改时间
);
分组变量表 pigsty.group_var
CREATE TABLE pigsty . group_var (
cls TEXT NOT NULL REFERENCES pigsty . group ( cls ),
key TEXT NOT NULL ,
value JSONB NULL ,
mtime TIMESTAMPTZ DEFAULT now (),
PRIMARY KEY ( cls , key )
);
主机变量表 pigsty.host_var
CREATE TABLE pigsty . host_var (
cls TEXT NOT NULL ,
ip INET NOT NULL ,
key TEXT NOT NULL ,
value JSONB NULL ,
mtime TIMESTAMPTZ DEFAULT now (),
PRIMARY KEY ( cls , ip , key ),
FOREIGN KEY ( cls , ip ) REFERENCES pigsty . host ( cls , ip )
);
核心视图 CMDB 提供了一系列视图,用于查询和展示配置数据:
视图名 说明 pigsty.inventory核心视图 :生成 Ansible 动态清单 JSONpigsty.raw_config原始配置的 JSON 格式展示 pigsty.global_config全局配置视图,合并默认值和全局变量 pigsty.group_config分组配置视图,包含主机列表和分组变量 pigsty.host_config主机配置视图,合并分组和主机级别变量 pigsty.pg_clusterPostgreSQL 集群视图 pigsty.pg_instancePostgreSQL 实例视图 pigsty.pg_databasePostgreSQL 数据库定义视图 pigsty.pg_usersPostgreSQL 用户定义视图 pigsty.pg_servicePostgreSQL 服务定义视图 pigsty.pg_hbaPostgreSQL HBA 规则视图 pigsty.pg_remote远程 PostgreSQL 实例视图
pigsty.inventory
SELECT text FROM pigsty . inventory ;
工具脚本 Pigsty 提供了三个便利脚本来管理 CMDB:
inventory_load 将 YAML 配置文件解析并导入到 CMDB 中:
bin/inventory_load # 加载默认的 pigsty.yml 到默认 CMDB
bin/inventory_load -p /path/to/conf.yml # 指定配置文件路径
bin/inventory_load -d "postgres://..." # 指定数据库连接 URL
bin/inventory_load -n myconfig # 指定配置名称
脚本会执行以下操作:
清空 pigsty 模式中的现有数据 解析 YAML 配置文件 将全局变量写入 global_var 表 将集群定义写入 group 表 将集群变量写入 group_var 表 将主机定义写入 host 表 将主机变量写入 host_var 表 环境变量
PIGSTY_HOME:Pigsty 安装目录,默认为 ~/pigstyMETADB_URL:数据库连接 URL,默认为 service=metainventory_cmdb 切换 Ansible 使用 CMDB 作为配置源:
脚本会执行以下操作:
创建动态清单脚本 ${PIGSTY_HOME}/inventory.sh 修改 ansible.cfg 将 inventory 设置为 inventory.sh 生成的 inventory.sh 内容如下:
#!/bin/bash
${ METADB_URL } -AXtwc 'SELECT text FROM pigsty.inventory;'
inventory_conf 切换回使用静态 YAML 配置文件:
脚本会修改 ansible.cfg 将 inventory 设置回 pigsty.yml。
使用流程 首次启用 CMDB 初始化 CMDB 模式 (通常在安装 Pigsty 时已自动完成):psql -f ~/pigsty/files/cmdb.sql
加载配置到数据库 :切换到 CMDB 模式 :验证配置 :ansible all --list-hosts # 列出所有主机
ansible-inventory --list # 查看完整清单
查询配置 启用 CMDB 后,您可以使用 SQL 灵活查询配置:
-- 查看所有集群
SELECT cls FROM pigsty . group ;
-- 查看某集群的所有主机
SELECT ip FROM pigsty . host WHERE cls = 'pg-meta' ;
-- 查看全局变量
SELECT key , value FROM pigsty . global_var ;
-- 查看某集群的变量
SELECT key , value FROM pigsty . group_var WHERE cls = 'pg-meta' ;
-- 查看所有 PostgreSQL 集群
SELECT cls , name , pg_databases , pg_users FROM pigsty . pg_cluster ;
-- 查看所有 PostgreSQL 实例
SELECT cls , ins , ip , seq , role FROM pigsty . pg_instance ;
-- 查看所有数据库定义
SELECT cls , datname , owner , encoding FROM pigsty . pg_database ;
-- 查看所有用户定义
SELECT cls , name , login , superuser FROM pigsty . pg_users ;
修改配置 您可以直接通过 SQL 修改配置:
-- 添加新集群
INSERT INTO pigsty . group ( cls ) VALUES ( 'pg-new' );
-- 添加集群变量
INSERT INTO pigsty . group_var ( cls , key , value )
VALUES ( 'pg-new' , 'pg_cluster' , '"pg-new"' );
-- 添加主机
INSERT INTO pigsty . host ( cls , ip ) VALUES ( 'pg-new' , '10.10.10.20' );
-- 添加主机变量
INSERT INTO pigsty . host_var ( cls , ip , key , value )
VALUES ( 'pg-new' , '10.10.10.20' , 'pg_seq' , '1' ),
( 'pg-new' , '10.10.10.20' , 'pg_role' , '"primary"' );
-- 修改全局变量
UPDATE pigsty . global_var SET value = '"new-value"' WHERE key = 'some_param' ;
-- 删除集群(级联删除主机和变量)
DELETE FROM pigsty . group WHERE cls = 'pg-old' ;
修改后立即生效,无需重新加载或重启任何服务。
切换回静态配置 如需切换回静态配置文件模式:
高级用法 配置导出 将 CMDB 中的配置导出为 YAML 格式:
psql service = meta -AXtwc "SELECT jsonb_pretty(jsonb_build_object('all', jsonb_build_object('children', children, 'vars', vars))) FROM pigsty.raw_config;"
或者使用 ansible-inventory 命令:
ansible-inventory --list --yaml > exported_config.yml
配置审计 利用 mtime 字段追踪配置变更:
-- 查看最近修改的全局变量
SELECT key , value , mtime FROM pigsty . global_var
ORDER BY mtime DESC LIMIT 10 ;
-- 查看某时间点之后的变更
SELECT * FROM pigsty . group_var
WHERE mtime > '2024-01-01' :: timestamptz ;
与外部系统集成 CMDB 使用标准 PostgreSQL,可以轻松与其他系统集成:
Web 管理界面 :通过 REST API(如 PostgREST)暴露配置数据CI/CD 流水线 :在部署脚本中直接读写数据库监控告警 :基于配置数据生成监控规则ITSM 系统 :与企业 CMDB 系统同步注意事项 数据一致性 :修改配置后,需要重新执行相应的 Ansible 剧本才能将变更应用到实际环境
备份 :CMDB 中的配置数据非常重要,请确保定期备份
权限 :建议为 CMDB 配置适当的数据库访问权限,避免误操作
事务 :批量修改配置时,建议在事务中进行,以便出错时回滚
连接池 :inventory.sh 脚本每次执行都会建立新连接,如果 Ansible 执行频繁,建议考虑使用连接池
小结 CMDB 是 Pigsty 配置管理的高级方案,适用于需要管理大量集群、复杂查询、外部集成或精细权限控制的场景。通过将配置数据存储在 PostgreSQL 中,您可以充分利用数据库的强大能力来管理基础设施配置。
功能 说明 数据存储 PostgreSQL pigsty 模式 动态清单 inventory.sh 脚本配置加载 bin/inventory_load切换到 CMDB bin/inventory_cmdb切换到 YAML bin/inventory_conf核心视图 pigsty.inventory
4 - 数据库高可用 Pigsty 使用 Patroni 实现了 PostgreSQL 的高可用,确保主库不可用时自动进行故障转移,由从库接管。
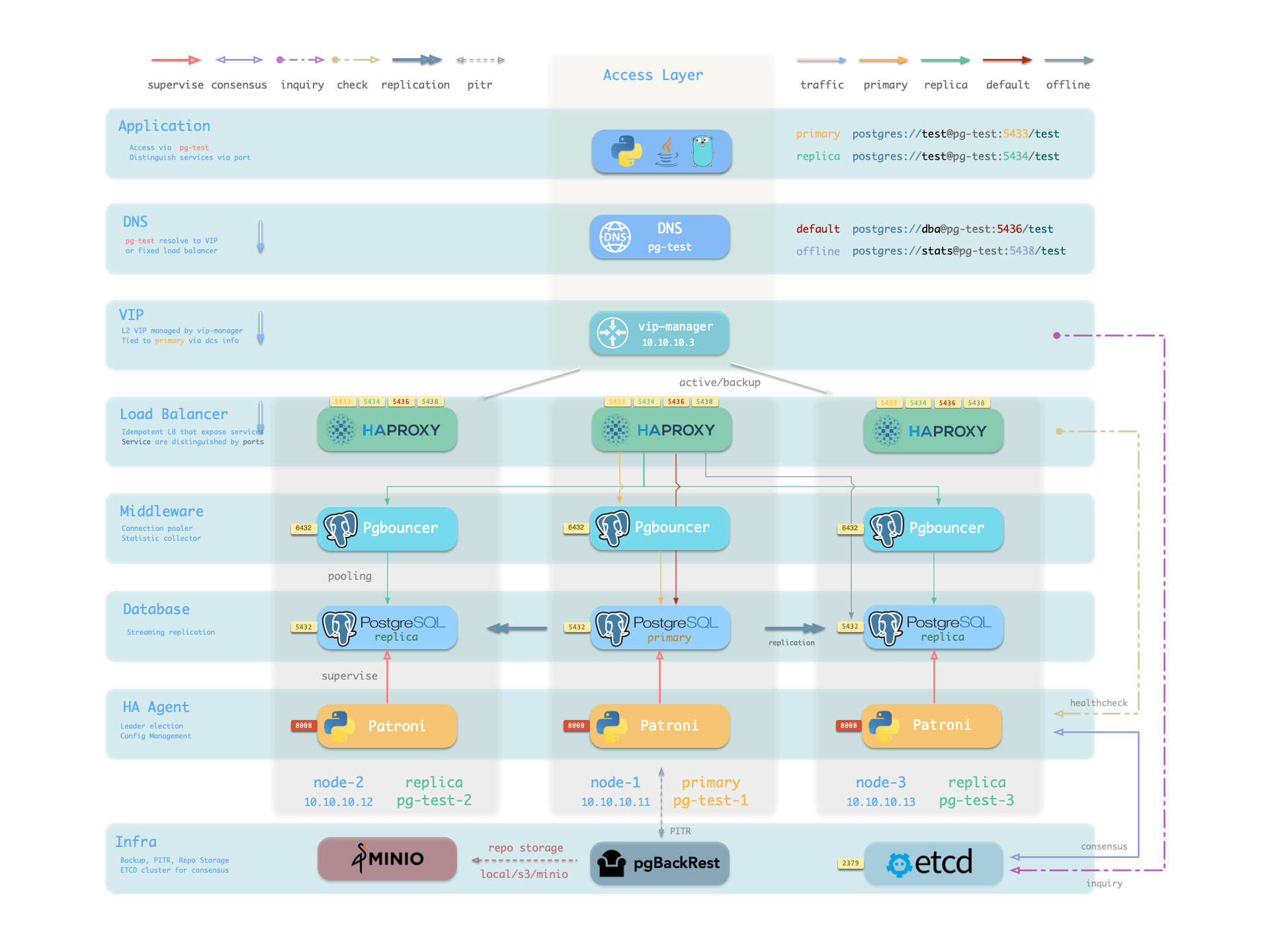
概览 Pigsty 的 PostgreSQL 集群带有开箱即用的高可用方案,由 Patroni Etcd HAProxy
当您的 PostgreSQL 集群含有两个或更多实例时,您无需任何配置即拥有了硬件故障自愈的数据库高可用能力 —— 只要集群中有任意实例存活,集群就可以对外提供完整的服务,而客户端只要连接至集群中的任意节点,即可获得完整的服务,而无需关心主从拓扑变化。
在默认配置下,主库故障恢复时间目标 RTO ≈ 30s,数据恢复点目标 RPO < 1MB;从库故障 RPO = 0,RTO ≈ 0 (闪断);在一致性优先模式下,可确保故障切换数据零损失:RPO = 0。以上指标均可通过参数,根据您的实际硬件条件与可靠性要求 按需配置
Pigsty 内置了 HAProxy 负载均衡器用于自动流量切换,提供 DNS/VIP/LVS 等多种接入方式供客户端选用。故障切换与主动切换对业务侧除零星闪断外几乎无感知,应用不需要修改连接串重启。
极小的维护窗口需求带来了极大的灵活便利:您完全可以在无需应用配合的情况下滚动维护升级整个集群。硬件故障可以等到第二天再抽空善后处置的特性,让研发,运维与 DBA 都能在故障时安心睡个好觉。
许多大型组织与核心机构已经在生产环境中长时间使用 Pigsty ,最大的部署有 25K CPU 核心与 220+ PostgreSQL 超大规格实例(64c / 512g / 3TB NVMe SSD);在这一部署案例中,五年内经历了数十次硬件故障与各类事故,但依然可以保持高于 99.999% 的总体可用性战绩。
高可用(High-Availability)解决什么问题?
将数据安全C/IA中的可用性提高到一个新高度:RPO ≈ 0, RTO < 30s。 获得无缝滚动维护的能力,最小化维护窗口需求,带来极大便利。 硬件故障可以立即自愈,无需人工介入,运维DBA可以睡个好觉。 从库可以用于承载只读请求,分担主库负载,让资源得以充分利用。 高可用有什么代价?
基础设施依赖:高可用需要依赖 DCS (etcd/zk/consul) 提供共识。 起步门槛增加:一个有意义的高可用部署环境至少需要 三个节点 。 额外的资源消耗:一个新从库就要消耗一份额外资源,不算大问题。 复杂度代价显著升高:备份成本显著加大,需要使用工具压制复杂度。 高可用的局限性
因为复制实时进⾏,所有变更被⽴即应⽤⾄从库。因此基于流复制的高可用方案⽆法应对⼈为错误与软件缺陷导致的数据误删误改。(例如:DROP TABLE,或 DELETE 数据)
此类故障需要使用 延迟集群 时间点恢复
配置策略 RTO RPO 单机 + 数据永久丢失,无法恢复 数据全部丢失 单机 + 单机 + 主从 + 主从 + 主从 +
原理 在 Pigsty 中,高可用架构的实现原理如下:
PostgreSQL 使⽤标准流复制搭建物理从库,主库故障时由从库接管。 Patroni 负责管理 PostgreSQL 服务器进程,处理高可用相关事宜。 Etcd 提供分布式配置存储(DCS)能力,并用于故障后的领导者选举 Patroni 依赖 Etcd 达成集群领导者共识,并对外提供健康检查接口。 HAProxy 对外暴露集群服务,并利⽤ Patroni 健康检查接口,自动分发流量至健康节点。 vip-manager 提供一个可选的二层 VIP,从 Etcd 中获取领导者信息,并将 VIP 绑定在集群主库所在节点上。 当主库故障时,将触发新一轮领导者竞选,集群中最为健康的从库将胜出(LSN位点最高,数据损失最小者),并被提升为新的主库。 胜选从库提升后,读写流量将立即路由至新的主库。
主库故障影响是 写服务短暂不可用 :从主库故障到新主库提升期间,写入请求将被阻塞或直接失败,不可用时长通常在 15秒 ~ 30秒,通常不会超过 1 分钟。
当从库故障时,只读流量将路由至其他从库,如果所有从库都故障,只读流量才会最终由主库承载。
从库故障的影响是 部分只读查询闪断 :当前从库上正在运行查询将由于连接重置而中止,并立即由其他可用从库接管。
故障检测由 Patroni 和 Etcd 共同完成,集群领导者将持有一个租约,
如果集群领导者因为故障而没有及时续租(10s),租约将会被释放,并触发 故障切换 (Failover) 与新一轮集群选举。
即使没有出现任何故障,您依然可以主动通过 主动切换
利弊权衡 故障恢复时间目标 (RTO )与 数据恢复点目标 (RPO )是高可用集群设计时需要仔细进行利弊权衡的两个参数。
Pigsty 使用的 RTO 与 RPO 默认值满足绝大多数场景下的可靠性要求,您可以根据您的硬件水平,网络质量,业务需求来合理调整它们。
RTO 与 RPO 并非越小越好!
过小的 RTO 将增大误报几率,过小的 RPO 将降低成功自动切换的概率。
故障切换时的不可用时长上限由 pg_rtoRTO 默认值为 30s,增大它将导致更长的主库故障转移写入不可用时长,而减少它将增加误报故障转移率(例如,由短暂网络抖动导致的反复切换)。
潜在数据丢失量的上限由 pg_rpo1MB,减小这个值可以降低故障切换时的数据损失上限,但也会增加故障时因为从库不够健康(落后太久)而拒绝自动切换的概率。
Pigsty 默认使用可用性优先 模式,这意味着当主库故障时,它将尽快进行故障转移,尚未复制到从库的数据可能会丢失(常规万兆网络下,复制延迟在通常在几KB到100KB)。
如果您需要确保故障切换时不丢失任何数据,您可以使用 crit.yml
相关参数 参数名称: pg_rto, 类型: int, 层次:C
以秒为单位的恢复时间目标(RTO)。这将用于计算 Patroni 的 TTL 值,默认为 30 秒。
如果主实例在这么长时间内失踪,将触发新的领导者选举,此值并非越低越好,它涉及到利弊权衡:
减小这个值可以减少集群故障转移期间的不可用时间(无法写入), 但会使集群对短期网络抖动更加敏感,从而增加误报触发故障转移的几率。
您需要根据网络状况和业务约束来配置这个值,在 故障几率 和 故障影响 之间做出权衡 。
参数名称: pg_rpo, 类型: int, 层次:C
以字节为单位的恢复点目标(RPO),默认值:1048576。
默认为 1MiB,这意味着在故障转移期间最多可以容忍 1MiB 的数据丢失。
当主节点宕机并且所有副本都滞后时,你必须做出一个艰难的选择:
是马上提升一个从库成为新的主库,付出可接受的数据丢失代价(例如,少于 1MB),并尽快将系统恢复服务。
还是等待主库重新上线(可能永远不会)以避免任何数据丢失,或放弃自动故障切换,等人工介入作出最终决策。
您需要根据业务的需求偏好配置这个值,在 可用性 和 一致性 之间进行 利弊权衡 。
此外,您始终可以通过启用同步提交(例如:使用 crit.yml 模板),通过牺牲集群一部分延迟/吞吐性能来强制确保 RPO = 0。
对于数据一致性至关重要
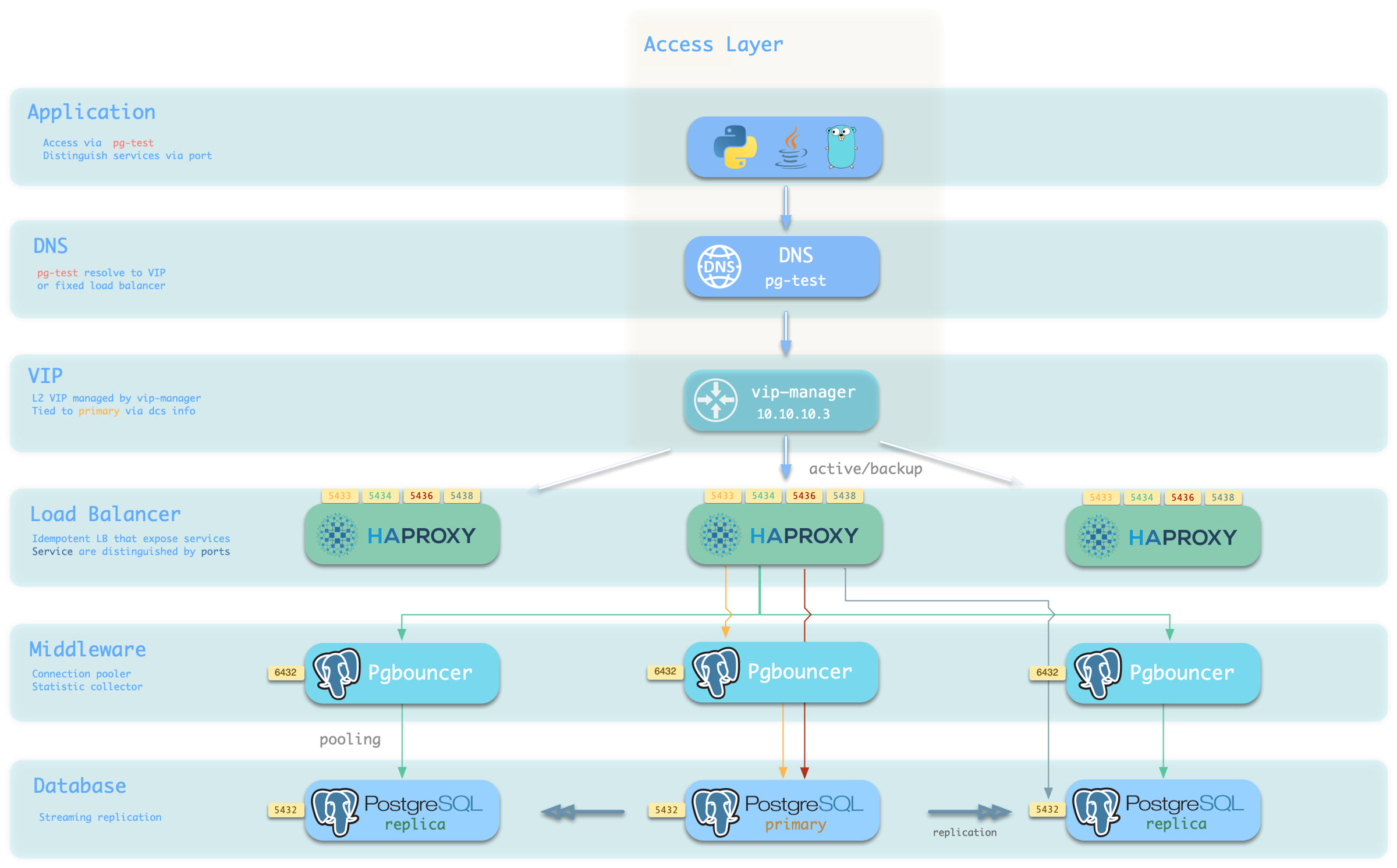
4.1 - 服务接入 Pigsty 使用 HAProxy 提供服务接入,并提供可选的 pgBouncer 池化连接,以及可选的 L2 VIP 与 DNS 接入。
分离读写操作,正确路由流量,稳定可靠地交付 PostgreSQL 集群提供的能力。
服务 是一种抽象:它是数据库集群对外提供能力的形式,并封装了底层集群的细节。
服务对于生产环境中的稳定接入 至关重要,在高可用 集群自动故障时方显其价值,单机用户 通常不需要操心这个概念。
单机用户 “服务” 的概念是给生产环境用的,个人用户/单机集群可以不折腾,直接拿实例名/IP地址访问数据库。
例如,Pigsty 默认的单节点 pg-meta.meta 数据库,就可以直接用下面三个不同的用户连接上去。
psql postgres://dbuser_dba:[email protected] /meta # 直接用 DBA 超级用户连上去
psql postgres://dbuser_meta:[email protected] /meta # 用默认的业务管理员用户连上去
psql postgres://dbuser_view:DBUser.View@pg-meta/meta # 用默认的只读用户走实例域名连上去
服务概述 在真实世界生产环境中,我们会使用基于复制的主从数据库集群。集群中有且仅有一个实例作为领导者(主库 )可以接受写入。
而其他实例(从库 )则会从持续从集群领导者获取变更日志,与领导者保持一致。同时,从库还可以承载只读请求,在读多写少的场景下可以显著分担主库的负担,
因此对集群的写入请求与只读请求进行区分,是一种十分常见的实践。
此外对于高频短连接的生产环境,我们还会通过连接池中间件(Pgbouncer)对请求进行池化,减少连接与后端进程的创建开销。但对于ETL与变更执行等场景,我们又需要绕过连接池,直接访问数据库。
同时,高可用集群在故障时会出现故障切换(Failover),故障切换会导致集群的领导者出现变更。因此高可用的数据库方案要求写入流量可以自动适配集群的领导者变化。
这些不同的访问需求(读写分离,池化与直连,故障切换自动适配)最终抽象出 服务 (Service)的概念。
通常来说,数据库集群都必须提供这种最基础的服务:
对于生产数据库集群,至少应当提供这两种服务:
读写服务(primary) :写入数据:只能由主库所承载。只读服务(replica) :读取数据:可以由从库承载,没有从库时也可由主库承载此外,根据具体的业务场景,可能还会有其他的服务,例如:
默认直连服务(default) :允许(管理)用户,绕过连接池直接访问数据库的服务离线从库服务(offline) :不承接线上只读流量的专用从库,用于ETL与分析查询同步从库服务(standby) :没有复制延迟的只读服务,由同步备库 /主库处理只读查询延迟从库服务(delayed) :访问同一个集群在一段时间之前的旧数据,由延迟从库 来处理接入服务 Pigsty的服务交付边界止步于集群的HAProxy,用户可以用各种手段访问这些负载均衡器。
典型的做法是使用 DNS 或 VIP 接入,将其绑定在集群所有或任意数量的负载均衡器上。
你可以使用不同的 主机 & 端口 组合,它们以不同的方式提供 PostgreSQL 服务。
主机
类型 样例 描述 集群域名 pg-test通过集群域名访问(由 dnsmasq @ infra 节点解析) 集群 VIP 地址 10.10.10.3通过由 vip-manager 管理的 L2 VIP 地址访问,绑定到主节点 实例主机名 pg-test-1通过任何实例主机名访问(由 dnsmasq @ infra 节点解析) 实例 IP 地址 10.10.10.11访问任何实例的 IP 地址
端口
Pigsty 使用不同的 端口 来区分 pg services
端口 服务 类型 描述 5432 postgres 数据库 直接访问 postgres 服务器 6432 pgbouncer 中间件 访问 postgres 前先通过连接池中间件 5433 primary 服务 访问主 pgbouncer (或 postgres) 5434 replica 服务 访问备份 pgbouncer (或 postgres) 5436 default 服务 访问主 postgres 5438 offline 服务 访问离线 postgres
组合
# 通过集群域名访问
postgres://test@pg-test:5432/test # DNS -> L2 VIP -> 主直接连接
postgres://test@pg-test:6432/test # DNS -> L2 VIP -> 主连接池 -> 主
postgres://test@pg-test:5433/test # DNS -> L2 VIP -> HAProxy -> 主连接池 -> 主
postgres://test@pg-test:5434/test # DNS -> L2 VIP -> HAProxy -> 备份连接池 -> 备份
postgres://dbuser_dba@pg-test:5436/test # DNS -> L2 VIP -> HAProxy -> 主直接连接 (用于管理员)
postgres://dbuser_stats@pg-test:5438/test # DNS -> L2 VIP -> HAProxy -> 离线直接连接 (用于 ETL/个人查询)
# 通过集群 VIP 直接访问
postgres://[email protected] :5432/test # L2 VIP -> 主直接访问
postgres://[email protected] :6432/test # L2 VIP -> 主连接池 -> 主
postgres://[email protected] :5433/test # L2 VIP -> HAProxy -> 主连接池 -> 主
postgres://[email protected] :5434/test # L2 VIP -> HAProxy -> 备份连接池 -> 备份
postgres://[email protected] :5436/test # L2 VIP -> HAProxy -> 主直接连接 (用于管理员)
postgres://[email protected] ::5438/test # L2 VIP -> HAProxy -> 离线直接连接 (用于 ETL/个人查询)
# 直接指定任何集群实例名
postgres://test@pg-test-1:5432/test # DNS -> 数据库实例直接连接 (单例访问)
postgres://test@pg-test-1:6432/test # DNS -> 连接池 -> 数据库
postgres://test@pg-test-1:5433/test # DNS -> HAProxy -> 连接池 -> 数据库读/写
postgres://test@pg-test-1:5434/test # DNS -> HAProxy -> 连接池 -> 数据库只读
postgres://dbuser_dba@pg-test-1:5436/test # DNS -> HAProxy -> 数据库直接连接
postgres://dbuser_stats@pg-test-1:5438/test # DNS -> HAProxy -> 数据库离线读/写
# 直接指定任何集群实例 IP 访问
postgres://[email protected] :5432/test # 数据库实例直接连接 (直接指定实例, 没有自动流量分配)
postgres://[email protected] :6432/test # 连接池 -> 数据库
postgres://[email protected] :5433/test # HAProxy -> 连接池 -> 数据库读/写
postgres://[email protected] :5434/test # HAProxy -> 连接池 -> 数据库只读
postgres://[email protected] :5436/test # HAProxy -> 数据库直接连接
postgres://[email protected] :5438/test # HAProxy -> 数据库离线读-写
# 智能客户端:通过URL读写分离
postgres://[email protected] :6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs= primary
postgres://[email protected] :6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs= prefer-standby
5 - 时间点恢复 Pigsty 使用 pgBackRest 实现了 PostgreSQL 时间点恢复,允许用户回滚至备份策略容许范围内的任意时间点。
您可以将集群恢复回滚至过去任意时刻,避免软件缺陷与人为失误导致的数据损失。
Pigsty 的 PostgreSQL 集群带有自动配置的时间点恢复(PITR)方案,基于备份组件 pgBackRest MinIO
高可用方案 时间点恢复 (Point in Time Recovery, PITR)能力,无需额外配置即默认启用。
Pigsty 为您提供了基础备份与 WAL 归档的默认配置,您可以使用本地目录与磁盘,亦或专用的 MinIO 集群或 S3 对象存储服务来存储备份并实现异地容灾。
当您使用本地磁盘时,默认保留恢复至过去一天内的任意时间点的能力。当您使用 MinIO 或 S3 时,默认保留恢复至过去一周内的任意时间点的能力。
只要存储空间管够,您尽可保留任意长地可恢复时间段,丰俭由人。
时间点恢复(PITR)解决什么问题?
容灾能⼒增强:RPO 从 ∞ 降⾄ ⼗⼏MB, RTO 从 ∞ 降⾄ ⼏⼩时/⼏刻钟。 确保数据安全:C/I/A 中的 数据完整性 :避免误删导致的数据⼀致性问题。 确保数据安全:C/I/A 中的 数据可⽤性 :提供对“永久不可⽤”这种灾难情况的兜底 单实例配置策略 事件 RTO RPO 宕机 永久丢失 全部丢失 宕机 宕机
时间点恢复有什么代价?
降低数据安全中的 C:机密性 ,产生额外泄漏点,需要额外对备份进⾏保护。 额外的资源消耗:本地存储或⽹络流量 / 带宽开销,通常并不是⼀个问题。 复杂度代价升⾼:⽤户需要付出备份管理成本。 时间点恢复的局限性
如果只有 PITR 用于故障恢复,则 RTO 与 RPO 指标相比 高可用方案
RTO :如果只有单机 + PITR,恢复时长取决于备份大小与网络/磁盘带宽,从十几分钟到几小时,几天不等。RPO :如果只有单机 + PITR,宕机时可能丢失少量数据,一个或几个 WAL 日志段文件可能尚未归档,损失 16 MB 到⼏⼗ MB 不等的数据。除了 PITR 延迟集群
原理 时间点恢复允许您将集群恢复回滚至过去的“任意时刻”,避免软件缺陷与人为失误导致的数据损失。要做到这一点,首先需要做好两样准备工作:基础备份 WAL归档 基础备份 ,允许用户将数据库恢复至备份时的状态,而同时拥有从某个基础备份开始的 WAL归档 ,允许用户将数据库恢复至基础备份时刻之后的任意时间点。
详细原理,请参阅:基础备份与时间点恢复 PGSQL管理:备份恢复
基础备份 Pigsty 使用 pgbackrest 管理 PostgreSQL 备份。pgBackRest 将在所有集群实例上初始化空仓库,但只会在集群主库上实际使用仓库。
pgBackRest 支持三种备份模式:全量备份 ,增量备份 ,差异备份,其中前两者最为常用。
全量备份将对数据库集群取一个当前时刻的全量物理快照,增量备份会记录当前数据库集群与上一次全量备份之间的差异。
Pigsty 为备份提供了封装命令:/pg/bin/pg-backup [full|incr]。您可以通过 Crontab 或任何其他任务调度系统,按需定期制作基础备份。
WAL归档 Pigsty 默认在集群主库上启⽤了 WAL 归档,并使⽤ pgbackrest 命令行工具持续推送 WAL 段⽂件至备份仓库。
pgBackRest 会⾃动管理所需的 WAL ⽂件,并根据备份的保留策略及时清理过期的备份,与其对应的 WAL 归档⽂件。
如果您不需要 PITR 功能,可以通过 配置集群 archive_mode: off 来关闭 WAL 归档,移除 node_crontab
实现 默认情况下,Pigsty提供了两种预置备份策略 :默认使用本地文件系统备份仓库,在这种情况下每天进行一次全量备份,确保用户任何时候都能回滚至一天内的任意时间点。备选策略使用专用的 MinIO 集群或S3存储备份,每周一全备,每天一增备,默认保留两周的备份与WAL归档。
Pigsty 使用 pgBackRest 管理备份,接收 WAL 归档,执行 PITR。备份仓库可以进行灵活配置(pgbackrest_repolocal),但也可以使用其他磁盘路径,或使用自带的可选 MinIO 服务(minio)与云上 S3 服务。
pgbackrest_enabled : true # 在 pgsql 主机上启用 pgBackRest 吗?
pgbackrest_clean : true # 初始化时删除 pg 备份数据?
pgbackrest_log_dir : /pg/log/pgbackrest # pgbackrest 日志目录,默认为 `/pg/log/pgbackrest`
pgbackrest_method : local # pgbackrest 仓库方法:local, minio, [用户定义...]
pgbackrest_repo : # pgbackrest 仓库:https://pgbackrest.org/configuration.html#section-repository
local : # 默认使用本地 posix 文件系统的 pgbackrest 仓库
path : /pg/backup # 本地备份目录,默认为 `/pg/backup`
retention_full_type : count # 按计数保留完整备份
retention_full : 2 # 使用本地文件系统仓库时,最多保留 3 个完整备份,至少保留 2 个
minio : # pgbackrest 的可选 minio 仓库
type : s3 # minio 是与 s3 兼容的,所以使用 s3
s3_endpoint : sss.pigsty # minio 端点域名,默认为 `sss.pigsty`
s3_region : us-east-1 # minio 区域,默认为 us-east-1,对 minio 无效
s3_bucket : pgsql # minio 桶名称,默认为 `pgsql`
s3_key : pgbackrest # pgbackrest 的 minio 用户访问密钥
s3_key_secret : S3User.Backup # pgbackrest 的 minio 用户秘密密钥
s3_uri_style : path # 对 minio 使用路径风格的 uri,而不是主机风格
path : /pgbackrest # minio 备份路径,默认为 `/pgbackrest`
storage_port : 9000 # minio 端口,默认为 9000
storage_ca_file : /etc/pki/ca.crt # minio ca 文件路径,默认为 `/etc/pki/ca.crt`
bundle : y # 将小文件打包成一个文件
cipher_type : aes-256-cbc # 为远程备份仓库启用 AES 加密
cipher_pass : pgBackRest # AES 加密密码,默认为 'pgBackRest'
retention_full_type : time # 在 minio 仓库上按时间保留完整备份
retention_full : 14 # 保留过去 14 天的完整备份
# 您还可以添加其他的可选备份仓库,例如 S3,用于异地容灾
Pigsty 参数 pgbackrest_repo/etc/pgbackrest/pgbackrest.conf 配置文件中的仓库定义。
例如,如果您定义了一个美西区的 S3 仓库用于存储冷备份,可以使用下面的参考配置。
s3 : # ------> /etc/pgbackrest/pgbackrest.conf
repo1-type : s3 # ----> repo1-type=s3
repo1-s3-region : us-west-1 # ----> repo1-s3-region=us-west-1
repo1-s3-endpoint : s3-us-west-1.amazonaws.com # ----> repo1-s3-endpoint=s3-us-west-1.amazonaws.com
repo1-s3-key : '<your_access_key>' # ----> repo1-s3-key=<your_access_key>
repo1-s3-key-secret : '<your_secret_key>' # ----> repo1-s3-key-secret=<your_secret_key>
repo1-s3-bucket : pgsql # ----> repo1-s3-bucket=pgsql
repo1-s3-uri-style : host # ----> repo1-s3-uri-style=host
repo1-path : /pgbackrest # ----> repo1-path=/pgbackrest
repo1-bundle : y # ----> repo1-bundle=y
repo1-cipher-type : aes-256-cbc # ----> repo1-cipher-type=aes-256-cbc
repo1-cipher-pass : pgBackRest # ----> repo1-cipher-pass=pgBackRest
repo1-retention-full-type : time # ----> repo1-retention-full-type=time
repo1-retention-full : 90 # ----> repo1-retention-full=90
恢复 您可以直接使用以下封装命令可以用于 PostgreSQL 数据库集群的 时间点恢复 。
Pigsty 默认使用增量差分并行恢复,允许您以最快速度恢复到指定时间点。
pg-pitr # 恢复到WAL存档流的结束位置(例如在整个数据中心故障的情况下使用)
pg-pitr -i # 恢复到最近备份完成的时间(不常用)
pg-pitr --time= "2022-12-30 14:44:44+08" # 恢复到指定的时间点(在删除数据库或表的情况下使用)
pg-pitr --name= "my-restore-point" # 恢复到使用 pg_create_restore_point 创建的命名恢复点
pg-pitr --lsn= "0/7C82CB8" -X # 在LSN之前立即恢复
pg-pitr --xid= "1234567" -X -P # 在指定的事务ID之前立即恢复,然后将集群直接提升为主库
pg-pitr --backup= latest # 恢复到最新的备份集
pg-pitr --backup= 20221108-105325 # 恢复到特定备份集,备份集可以使用 pgbackrest info 列出
pg-pitr # pgbackrest --stanza=pg-meta restore
pg-pitr -i # pgbackrest --stanza=pg-meta --type=immediate restore
pg-pitr -t "2022-12-30 14:44:44+08" # pgbackrest --stanza=pg-meta --type=time --target="2022-12-30 14:44:44+08" restore
pg-pitr -n "my-restore-point" # pgbackrest --stanza=pg-meta --type=name --target=my-restore-point restore
pg-pitr -b 20221108-105325F # pgbackrest --stanza=pg-meta --type=name --set=20221230-120101F restore
pg-pitr -l "0/7C82CB8" -X # pgbackrest --stanza=pg-meta --type=lsn --target="0/7C82CB8" --target-exclusive restore
pg-pitr -x 1234567 -X -P # pgbackrest --stanza=pg-meta --type=xid --target="0/7C82CB8" --target-exclusive --target-action=promote restore
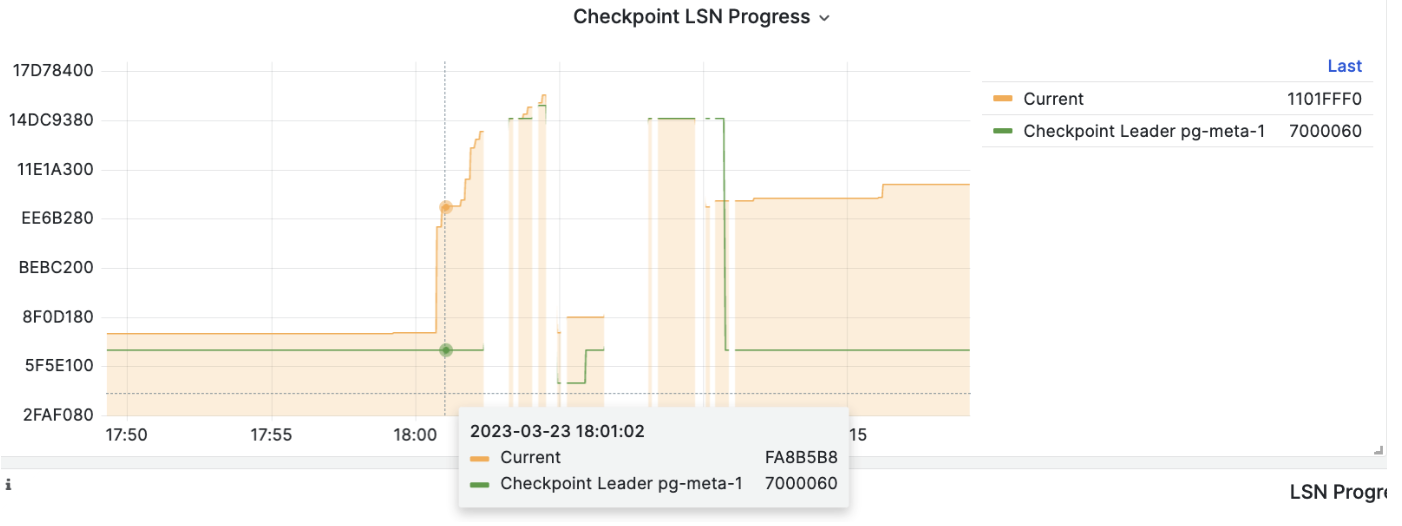
在执行 PITR 时,您可以使用 Pigsty 监控系统观察集群 LSN 位点状态,判断是否成功恢复到指定的时间点,事务点,LSN位点,或其他点位。
6 - 监控系统 Pigsty 的监控系统是如何架构与实现的,被监控的目标对象又是如何被自动纳入管理的。
7 - 安全合规 身份认证、访问控制、加密通信、审计日志,满足等保三级与 SOC2 合规要求。
Pigsty 的安全理念 默认安全 :开箱即用的安全配置,无需额外设置即可获得基本保护。
渐进配置 :企业级用户可根据需求,通过配置逐步增强安全措施。
纵深防御 :多层安全机制,即使某一层被突破,仍有其他层保护。
最小权限 :只授予用户完成任务所需的最低权限,降低风险。
默认安全配置 Pigsty 默认启用以下安全特性:
特性 默认配置 说明 密码加密 scram-sha-256PostgreSQL 最安全的密码哈希算法 SSL 支持 启用 客户端可选择使用 SSL 加密连接 本地 CA 自动生成 自签名 CA 签发服务器证书 HBA 分层 按来源控制 不同来源使用不同认证强度 角色系统 四层权限 只读/读写/管理员/离线 数据校验 启用 检测存储层数据损坏 审计日志 启用 记录连接和慢查询
可增强配置 通过额外配置可启用更高安全级别:
特性 配置方式 安全等级 密码强度检查 启用 passwordcheck 扩展 等保三级 强制 SSL HBA 使用 hostssl 等保三级 客户端证书 HBA 使用 cert 认证 金融级 备份加密 配置 cipher_type 合规要求 防火墙 配置 node_firewall_mode 基础设施
如果您只有一分钟,请记住这张图:
flowchart TB
subgraph L1["🌐 第 1 层:网络安全"]
L1A["防火墙 + SSL/TLS 加密 + HAProxy 代理"]
L1B["谁能连进来?连接是否加密?"]
end
subgraph L2["🔑 第 2 层:身份认证"]
L2A["HBA 规则 + SCRAM-SHA-256 密码 + 证书认证"]
L2B["你是谁?怎么证明?"]
end
subgraph L3["👤 第 3 层:访问控制"]
L3A["角色系统 + 对象权限 + 数据库隔离"]
L3B["你能做什么?能访问哪些数据?"]
end
subgraph L4["🔒 第 4 层:数据安全"]
L4A["数据校验 + 备份加密 + 审计日志"]
L4B["数据完整吗?操作有记录吗?"]
end
L1 --> L2 --> L3 --> L4 核心价值 :开箱即用的企业级安全配置,默认启用最佳实践,额外配置可达等保三级与 SOC 2 合规要求。
本章内容 章节 说明 核心问题 安全概述 安全能力总览与检查清单 整体安全架构是怎样的? 身份认证 HBA 规则、密码策略、证书认证 如何验证用户身份? 访问控制 角色系统、权限模型、数据库隔离 如何控制用户权限? 加密通信 SSL/TLS、本地 CA、证书管理 如何保护数据传输? 合规清单 等保三级与 SOC2 详细对照 如何满足合规要求?
为什么安全很重要? 数据泄露的代价 flowchart LR
Breach["💥 数据泄露"]
subgraph Direct["💰 直接损失"]
D1["监管罚款<br/>GDPR 可达全球营收 4%"]
D2["法律诉讼费用"]
D3["客户赔偿"]
end
subgraph Indirect["📉 间接损失"]
I1["品牌声誉受损"]
I2["客户信任丧失"]
I3["业务中断"]
end
subgraph Compliance["⚠️ 合规风险"]
C1["等保三级:责任追究"]
C2["SOC 2:认证撤销"]
C3["行业准入:被禁止经营"]
end
Breach --> Direct
Breach --> Indirect
Breach --> Compliance 默认用户与密码 Pigsty 默认创建以下系统用户:
用户 用途 默认密码 部署后操作 postgres系统超级用户 无密码(仅本地) 保持无密码 dbuser_dba管理员用户 DBUser.DBA必须修改 dbuser_monitor监控用户 DBUser.Monitor必须修改 replicator复制用户 DBUser.Replicator必须修改
# pigsty.yml - 修改默认密码
pg_admin_password : 'YourSecurePassword123!'
pg_monitor_password : 'AnotherSecurePass456!'
pg_replication_password : 'ReplicationPass789!'
⚠️ 重要 :生产环境部署后,请立即 修改这些默认密码!
角色与权限系统 Pigsty 提供开箱即用的四层角色系统:
flowchart TB
subgraph Admin["🔴 dbrole_admin(管理员)"]
A1["继承 dbrole_readwrite"]
A2["可以创建/删除/修改对象 DDL"]
A3["适用于:业务管理员、需要建表的应用"]
end
subgraph RW["🟡 dbrole_readwrite(读写)"]
RW1["继承 dbrole_readonly"]
RW2["可以 INSERT/UPDATE/DELETE"]
RW3["适用于:生产业务账号"]
end
subgraph RO["🟢 dbrole_readonly(只读)"]
RO1["可以 SELECT 所有表"]
RO2["适用于:报表查询、数据分析"]
end
subgraph Offline["🔵 dbrole_offline(离线)"]
OFF1["只能访问离线实例"]
OFF2["适用于:ETL、个人分析、慢查询"]
end
Admin --> |继承| RW
RW --> |继承| RO 创建业务用户 pg_users :
# 只读用户 - 用于报表查询
- name : dbuser_report
password : ReportUser123
roles : [ dbrole_readonly]
pgbouncer : true
# 读写用户 - 用于生产业务
- name : dbuser_app
password : AppUser456
roles : [ dbrole_readwrite]
pgbouncer : true
# 管理员用户 - 用于 DDL 操作
- name : dbuser_admin
password : AdminUser789
roles : [ dbrole_admin]
pgbouncer : true
HBA 访问控制 HBA(Host-Based Authentication)控制"谁可以从哪里连接":
flowchart LR
subgraph Sources["连接来源"]
S1["🏠 本地 Socket"]
S2["💻 localhost"]
S3["🏢 内网 CIDR"]
S4["🛡️ 管理节点"]
S5["🌐 外网"]
end
subgraph Auth["认证方式"]
A1["ident/peer<br/>OS 用户映射,最安全"]
A2["scram-sha-256<br/>密码认证"]
A3["scram-sha-256 + SSL<br/>强制 SSL"]
end
S1 --> A1
S2 --> A2
S3 --> A2
S4 --> A3
S5 --> A3
Note["📋 规则按顺序匹配<br/>第一条匹配的规则生效"] 自定义 HBA 规则 pg_hba_rules :
# 允许应用服务器从内网连接
- {user: dbuser_app, db: mydb, addr: '10.10.10.0/24', auth : scram-sha-256}
# 强制某些用户使用 SSL
- {user: admin, db: all, addr: world, auth : ssl}
# 要求证书认证(最高安全级别)
- {user: secure_user, db: all, addr: world, auth : cert}
加密通信 SSL/TLS 架构 sequenceDiagram
participant Client as 🖥️ 客户端
participant Server as 🐘 PostgreSQL
Client->>Server: 1. ClientHello
Server->>Client: 2. ServerHello
Server->>Client: 3. 服务器证书
Client->>Server: 4. 客户端密钥
Client->>Server: 5. 加密通道建立
Server->>Client: 5. 加密通道建立
rect rgb(200, 255, 200)
Note over Client,Server: 🔒 加密数据传输
Client->>Server: 6. 应用数据(加密)
Server->>Client: 6. 应用数据(加密)
end
Note over Client,Server: ✅ 防止窃听 ✅ 防止篡改 ✅ 验证服务器身份 本地 CA Pigsty 自动生成本地 CA 并签发证书:
/etc/pki/
├── ca.crt # CA 证书(公开)
├── ca.key # CA 私钥(保密!)
└── server.crt/key # 服务器证书/私钥
⚠️ 重要 :请安全备份 ca.key,丢失后需要重新签发所有证书!
合规对照 等保三级(GB/T 22239-2019) 安全要求 Pigsty 默认 可配置达到 说明 身份鉴别唯一性 ✅ ✅ 每个用户唯一标识 口令复杂度 ⚠️ ✅ 启用 passwordcheck 口令定期更换 ⚠️ ✅ 需要运维流程 双因素认证 ⚠️ ✅ 证书 + 密码 访问控制 ✅ ✅ HBA + 角色系统 最小权限原则 ✅ ✅ 四层角色模型 通信加密 ✅ ✅ SSL/TLS 审计日志 ✅ ✅ 连接日志 + 慢查询 数据完整性 ✅ ✅ 数据校验和 备份恢复 ✅ ✅ pgBackRest
SOC 2 Type II 控制点 Pigsty 支持 说明 CC6.1 逻辑访问控制 ✅ HBA + 角色系统 CC6.6 传输加密 ✅ SSL/TLS CC7.2 系统监控 ✅ Prometheus + Grafana CC9.1 业务连续性 ✅ 高可用 + PITR A1.2 数据恢复 ✅ pgBackRest 备份
图例 :✅ 默认满足 · ⚠️ 需要额外配置
安全检查清单 部署前 部署后(必做) 定期维护 快速配置示例 生产环境安全配置 # pigsty.yml - 生产环境安全配置示例
all :
vars :
# 修改默认密码(必须!)
pg_admin_password : 'SecureDBAPassword2024!'
pg_monitor_password : 'SecureMonitorPass2024!'
pg_replication_password : 'SecureReplPass2024!'
# 启用密码强度检查
pg_libs : 'passwordcheck, pg_stat_statements, auto_explain'
# 自定义 HBA 规则
pg_hba_rules :
# 应用服务器
- {user: app, db: appdb, addr: '10.10.10.0/24', auth : scram-sha-256}
# 管理员强制 SSL
- {user: dbuser_dba, db: all, addr: world, auth : ssl}
金融级安全配置 # 金融级配置 - 启用证书认证
pg_hba_rules :
# 交易系统使用证书认证
- {user: trade_user, db: trade, addr: world, auth : cert}
# 其他系统使用 SSL + 密码
- {user: all, db: all, addr: world, auth : ssl}
# 启用备份加密
pgbackrest_repo :
minio :
cipher_type : aes-256-cbc
cipher_pass : 'YourBackupEncryptionKey'
接下来 深入了解安全配置的细节:
👁️ 安全概述 :整体安全架构与检查清单 🔑 身份认证 👤 访问控制 🔐 加密通信 ✅ 合规清单 :等保三级与 SOC2 详细对照 相关话题:
7.1 - 本地 CA Pigsty 带有一套自签名的 CA 公私钥基础设施,用于签发 SSL 证书,加密网络通信流量。
Pigsty 部署默认启用了一些安全最佳实践:使用 SSL 加密网络流量,使用 HTTPS 加密 Web 界面。
为了实现这一功能,Pigsty 内置了本地自签名的 CA ,用于签发 SSL 证书,加密网络通信流量。
在默认情况下,SSL 与 HTTPS 是启用,但不强制使用的。对于有着较高安全要求的环境,您可以强制使用 SSL 与 HTTPS。
本地CA Pigsty 默认会在初始化时,在 ADMIN节点 ~/pigsty)中生成一个自签名的 CA。
当您需要使用 SSL,HTTPS,数字签名,签发数据库客户端证书,高级安全特性时,可以使用此 CA。
每一套 Pigsty 部署使用的 CA 都是唯一的,不同的 Pigsty 部署之间的 CA 是不相互信任的。
本地 CA 由两个文件组成,默认放置于 files/pki/ca
ca.crtca.key请保护好CA私钥文件
请妥善保管 CA 私钥文件,不要遗失,不要泄漏。我们建议您在完成 Pigsty 安装后及时备份此文件。
使用现有CA 如果您本身已经有 CA 公私钥基础设施,Pigsty 也可以配置为使用现有 CA 。
在执行部署前,将您的 CA 公钥与私钥文件放置于 files/pki/ca
files/pki/ca/ca.key # 核心的 CA 私钥文件,必须存在,如果不存在,默认会重新随机生成一个
files/pki/ca/ca.crt # 如果没有证书文件,Pigsty会自动重新从 CA 私钥生成新的根证书文件
当 Pigsty 执行 deploy.ymlinfra.ymlfiles/pki/ca 目录中的 ca.key 私钥文件存在,则会使用已有的 CA 。ca.crt 文件可以从 ca.key 私钥文件生成,所以如果没有证书文件,Pigsty 会自动重新从 CA 私钥生成新的根证书文件。
使用现有CA时请注意
您可以将 ca_methodcopy,确保 Pigsty 找不到本地 CA 时报错中止,而不是自行重新生成新的自签名 CA。
信任CA 在 Pigsty 安装过程中,ca.crtnode.ymlnode_ca/etc/pki/ca.crt
EL系操作系统与 Debian系操作系统默认信任的 CA 根证书路径不同,因此分发的路径与更新的方式也不同。
信任CA证书
EL
Debian / Ubuntu rm -rf /etc/pki/ca-trust/source/anchors/ca.crt
ln -s /etc/pki/ca.crt /etc/pki/ca-trust/source/anchors/ca.crt
/bin/update-ca-trust rm -rf /usr/local/share/ca-certificates/ca.crt
ln -s /etc/pki/ca.crt /usr/local/share/ca-certificates/ca.crt
/usr/sbin/update-ca-certificates Pigsty 默认会为基础设施节点上的 Web 系统使用的域名签发 HTTPS 证书,您可以 HTTPS 访问 Pigsty 的 Web 系统。
如果您希望在客户端电脑上浏览器访问时不要弹出“不受信任的 CA 证书”信息,可以将 ca.crt 分发至客户端电脑的信任证书目录中。
您可以双击 ca.crt 文件将其加入系统钥匙串,例如在 MacOS 系统中,需要打开“钥匙串访问” 搜索 pigsty-ca 然后“信任”此根证书
查看证书内容 使用以下命令,可以查阅 Pigsty CA 证书的内容
openssl x509 -text -in /etc/pki/ca.crt
本地 CA 根证书内容样例 Certificate:
Data:
Version: 3 (0x2)
Serial Number:
50:29:e3:60:96:93:f4:85:14:fe:44:81:73:b5:e1:09:2a:a8:5c:0a
Signature Algorithm: sha256WithRSAEncryption
Issuer: O=pigsty, OU=ca, CN=pigsty-ca
Validity
Not Before: Feb 7 00:56:27 2023 GMT
Not After : Jan 14 00:56:27 2123 GMT
Subject: O=pigsty, OU=ca, CN=pigsty-ca
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (4096 bit)
Modulus:
00:c1:41:74:4f:28:c3:3c:2b:13:a2:37:05:87:31:
....
e6:bd:69:a5:5b:e3:b4:c0:65:09:6e:84:14:e9:eb:
90:f7:61
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Subject Alternative Name:
DNS:pigsty-ca
X509v3 Key Usage:
Digital Signature, Certificate Sign, CRL Sign
X509v3 Basic Constraints: critical
CA:TRUE, pathlen:1
X509v3 Subject Key Identifier:
C5:F6:23:CE:BA:F3:96:F6:4B:48:A5:B1:CD:D4:FA:2B:BD:6F:A6:9C
Signature Algorithm: sha256WithRSAEncryption
Signature Value:
89:9d:21:35:59:6b:2c:9b:c7:6d:26:5b:a9:49:80:93:81:18:
....
9e:dd:87:88:0d:c4:29:9e
-----BEGIN CERTIFICATE-----
...
cXyWAYcvfPae3YeIDcQpng==
-----END CERTIFICATE-----
签发证书 如果您希望通过客户端证书认证,那么可以使用本地 CA 与 cert.yml
将证书的 CN 字段设置为数据库用户名即可:
./cert.yml -e cn = dbuser_dba
./cert.yml -e cn = dbuser_monitor
签发的证书会默认生成在 files/pki/misc/<cn>.{key,crt} 路径下。
7.2 - 访问控制 Pigsty 提供了标准的安全实践:密码与证书认证,开箱即用的权限模型,SSL加密网络流量,加密远程冷备份等。
Pigsty 提供了一套开箱即用的,基于角色系统 和权限系统 的访问控制模型。
权限控制很重要,但很多用户做不好。因此 Pigsty 提供了一套开箱即用的精简访问控制模型,为您的集群安全性提供一个兜底。
角色系统 Pigsty 默认的角色系统包含四个默认角色 和四个默认用户 :
角色名称 属性 所属 描述 dbrole_readonlyNOLOGIN角色:全局只读访问 dbrole_readwriteNOLOGINdbrole_readonly 角色:全局读写访问 dbrole_adminNOLOGINpg_monitor,dbrole_readwrite 角色:管理员/对象创建 dbrole_offlineNOLOGIN角色:受限的只读访问 postgresSUPERUSER系统超级用户 replicatorREPLICATIONpg_monitor,dbrole_readonly 系统复制用户 dbuser_dbaSUPERUSERdbrole_admin pgsql 管理用户 dbuser_monitorpg_monitor pgsql 监控用户
这些角色与用户 的详细定义如下所示:
pg_default_roles : # 全局默认的角色与系统用户
- { name: dbrole_readonly ,login: false ,comment : role for global read-only access }
- { name: dbrole_offline ,login: false ,comment : role for restricted read-only access }
- { name: dbrole_readwrite ,login: false ,roles: [dbrole_readonly] ,comment : role for global read-write access }
- { name: dbrole_admin ,login: false ,roles: [pg_monitor, dbrole_readwrite] ,comment : role for object creation }
- { name: postgres ,superuser: true ,comment : system superuser }
- { name: replicator ,replication: true ,roles: [pg_monitor, dbrole_readonly] ,comment : system replicator }
- { name: dbuser_dba ,superuser: true ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 ,comment : pgsql admin user }
- { name: dbuser_monitor ,roles: [pg_monitor] ,pgbouncer: true ,parameters : {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment : pgsql monitor user }
默认角色 Pigsty 中有四个默认角色:
业务只读 (dbrole_readonly): 用于全局只读访问的角色。如果别的业务想要此库只读访问权限,可以使用此角色。 业务读写 (dbrole_readwrite): 用于全局读写访问的角色,主属业务使用的生产账号应当具有数据库读写权限 业务管理员 (dbrole_admin): 拥有DDL权限的角色,通常用于业务管理员,或者需要在应用中建表的场景(比如各种业务软件) 离线只读访问 (dbrole_offline): 受限的只读访问角色(只能访问 offline 实例,通常是个人用户,ETL工具账号) 默认角色在 pg_default_roles
- { name: dbrole_readonly , login: false , comment : role for global read-only access } # 生产环境的只读角色
name: dbrole_offline , login: false , comment : role for restricted read-only access (offline instance) } # 受限的只读角色
name: dbrole_readwrite , login: false , roles: [dbrole_readonly], comment : role for global read-write access } # 生产环境的读写角色
name: dbrole_admin , login: false , roles: [pg_monitor, dbrole_readwrite] , comment : role for object creation } # 生产环境的 DDL 更改角色
默认用户 Pigsty 也有四个默认用户(系统用户):
超级用户 (postgres),集群的所有者和创建者,与操作系统 dbsu 名称相同。 复制用户 (replicator),用于主-从复制的系统用户。 监控用户 (dbuser_monitor),用于监控数据库和连接池指标的用户。 管理用户 (dbuser_dba),执行日常操作和数据库更改的管理员用户。 这4个默认用户的用户名/密码通过4对专用参数进行定义,并在很多地方引用:
在生产部署中记得更改这些密码,不要使用默认值!
pg_dbsu : postgres # 数据库超级用户名,这个用户名建议不要修改。
pg_dbsu_password : '' # 数据库超级用户密码,这个密码建议留空!禁止dbsu密码登陆。
pg_replication_username : replicator # 系统复制用户名
pg_replication_password : DBUser.Replicator # 系统复制密码,请务必修改此密码!
pg_monitor_username : dbuser_monitor # 系统监控用户名
pg_monitor_password : DBUser.Monitor # 系统监控密码,请务必修改此密码!
pg_admin_username : dbuser_dba # 系统管理用户名
pg_admin_password : DBUser.DBA # 系统管理密码,请务必修改此密码!
如果您修改默认用户的参数,在 pg_default_roles定义 即可:
- { name: postgres ,superuser: true ,comment : system superuser }
name: replicator ,replication: true ,roles: [pg_monitor, dbrole_readonly] ,comment : system replicator }
name: dbuser_dba ,superuser: true ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 , comment : pgsql admin user }
name: dbuser_monitor ,roles: [pg_monitor, dbrole_readonly] ,pgbouncer: true ,parameters : {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment : pgsql monitor user }
权限系统 Pigsty 拥有一套开箱即用的权限模型,该模型与默认角色 一起配合工作。
所有用户都可以访问所有模式。 只读用户(dbrole_readonly)可以从所有表中读取数据。(SELECT,EXECUTE) 读写用户(dbrole_readwrite)可以向所有表中写入数据并运行 DML。(INSERT,UPDATE,DELETE)。 管理员用户(dbrole_admin)可以创建对象并运行 DDL(CREATE,USAGE,TRUNCATE,REFERENCES,TRIGGER)。 离线用户(dbrole_offline)类似只读用户,但访问受到限制,只允许访问离线实例 (pg_role = 'offline' 或 pg_offline_query = true) 由管理员用户创建的对象将具有正确的权限。 所有数据库上都配置了默认权限,包括模板数据库。 数据库连接权限由数据库定义 管理。 默认撤销PUBLIC在数据库和public模式下的CREATE权限。 对象权限 数据库中新建对象的默认权限由参数 pg_default_privileges
- GRANT USAGE ON SCHEMAS TO dbrole_readonly
GRANT SELECT ON TABLES TO dbrole_readonly
GRANT SELECT ON SEQUENCES TO dbrole_readonly
GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
GRANT USAGE ON SCHEMAS TO dbrole_offline
GRANT SELECT ON TABLES TO dbrole_offline
GRANT SELECT ON SEQUENCES TO dbrole_offline
GRANT EXECUTE ON FUNCTIONS TO dbrole_offline
GRANT INSERT ON TABLES TO dbrole_readwrite
GRANT UPDATE ON TABLES TO dbrole_readwrite
GRANT DELETE ON TABLES TO dbrole_readwrite
GRANT USAGE ON SEQUENCES TO dbrole_readwrite
GRANT UPDATE ON SEQUENCES TO dbrole_readwrite
GRANT TRUNCATE ON TABLES TO dbrole_admin
GRANT REFERENCES ON TABLES TO dbrole_admin
GRANT TRIGGER ON TABLES TO dbrole_admin
GRANT CREATE ON SCHEMAS TO dbrole_admin
由管理员新创建 的对象,默认将会上述权限。使用 \ddp+ 可以查看这些默认权限:
类型 访问权限 函数 =X dbrole_readonly=X dbrole_offline=X dbrole_admin=X 模式 dbrole_readonly=U dbrole_offline=U dbrole_admin=UC 序列号 dbrole_readonly=r dbrole_offline=r dbrole_readwrite=wU dbrole_admin=rwU 表 dbrole_readonly=r dbrole_offline=r dbrole_readwrite=awd dbrole_admin=arwdDxt
默认权限 SQL 语句 ALTER DEFAULT PRIVILEGES
在 Pigsty 中,默认权限针对三个角色进行定义:
{ % for priv in pg_default_privileges % }
ALTER DEFAULT PRIVILEGES FOR ROLE {{ pg_dbsu }} {{ priv }} ;
{ % endfor % }
{ % for priv in pg_default_privileges % }
ALTER DEFAULT PRIVILEGES FOR ROLE {{ pg_admin_username }} {{ priv }} ;
{ % endfor % }
-- 对于其他业务管理员而言,它们应当在执行 DDL 前执行 SET ROLE dbrole_admin,从而使用对应的默认权限配置。
{ % for priv in pg_default_privileges % }
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" {{ priv }} ;
{ % endfor % }
这些内容将会被 PG集群初始化模板 pg-init-template.sql/pg/tmp/pg-init-template.sql。
该命令会在 template1 与 postgres 数据库中执行,新创建的数据库会通过模板 template1 继承这些默认权限配置。
也就是说,为了维持正确的对象权限,您必须用管理员用户 来执行 DDL,它们可以是:
{{ pg_dbsu }}postgres{{ pg_admin_username }}dbuser_dba授予了 dbrole_admin 角色的业务管理员用户(通过 SET ROLE 切换为 dbrole_admin 身份)。 使用 postgres 作为全局对象所有者是明智的。如果您希望以业务管理员用户身份创建对象,创建之前必须使用 SET ROLE dbrole_admin 来维护正确的权限。
当然,您也可以在数据库中通过 ALTER DEFAULT PRIVILEGE FOR ROLE <some_biz_admin> XXX 来显式对业务管理员授予默认权限。
数据库权限 在 Pigsty 中,数据库(Database)层面的权限在数据库定义 中被涵盖。
数据库有三个级别的权限:CONNECT、CREATE、TEMP,以及一个特殊的’权限’:OWNERSHIP。
- name : meta # 必选,`name` 是数据库定义中唯一的必选字段
owner : postgres # 可选,数据库所有者,默认为 postgres
allowconn : true # 可选,是否允许连接,默认为 true。显式设置 false 将完全禁止连接到此数据库
revokeconn : false # 可选,撤销公共连接权限。默认为 false,设置为 true 时,属主和管理员之外用户的 CONNECT 权限会被回收
如果 owner 参数存在,它作为数据库属主,替代默认的 {{ pg_dbsu }}postgres) 如果 revokeconn 为 false,所有用户都有数据库的 CONNECT 权限,这是默认的行为。 如果显式设置了 revokeconn 为 true:数据库的 CONNECT 权限将从 PUBLIC 中撤销:普通用户无法连接上此数据库 CONNECT 权限将被显式授予 {{ pg_replication_username }}、{{ pg_monitor_username }} 和 {{ pg_admin_username }}CONNECT 权限将 GRANT OPTION 被授予数据库属主,数据库属主用户可以自行授权其他用户连接权限。 revokeconn 选项可用于在同一个集群间隔离跨数据库访问,您可以为每个数据库创建不同的业务用户作为属主,并为它们设置 revokeconn 选项。示例:数据库隔离 pg-infra :
hosts :
10.10.10.40 : { pg_seq: 1, pg_role : primary }
10.10.10.41 : { pg_seq: 2, pg_role: replica , pg_offline_query : true }
vars :
pg_cluster : pg-infra
pg_users :
- { name: dbuser_confluence, password: mc2iohos , pgbouncer: true, roles : [ dbrole_admin ] }
- { name: dbuser_gitlab, password: sdf23g22sfdd , pgbouncer: true, roles : [ dbrole_readwrite ] }
- { name: dbuser_jira, password: sdpijfsfdsfdfs , pgbouncer: true, roles : [ dbrole_admin ] }
pg_databases :
- { name: confluence , revokeconn: true, owner: dbuser_confluence , connlimit : 100 }
- { name: gitlab , revokeconn: true, owner: dbuser_gitlab, connlimit : 100 }
- { name: jira , revokeconn: true, owner: dbuser_jira , connlimit : 100 }
CREATE权限 出于安全考虑,Pigsty 默认从 PUBLIC 撤销数据库上的 CREATE 权限,从 PostgreSQL 15 开始这也是默认行为。
数据库属主总是可以根据实际需要,来自行调整 CREATE 权限。